Rethinking the Value of Network Pruning
This work contradicts the “Lottery Ticket Hypothesis” paper. While in the latter, it is said that training large networks makes it more likely to have good features and acheive good performance, this new paper shows that training a small network from scratch gives comparable or better results than pruning and fine-tuning a large model.
They have two main conclusions:
- “training a small pruned model from scratch can almost always achieve the same or higher level of accuracy than a model fine-tuned from inherited weights”.
- “the value of automatic pruning algorithms could be regarded as searching efficient architectures”. In other words, pruning is good for finding a new architecture that you will then train from scratch.
Experiments
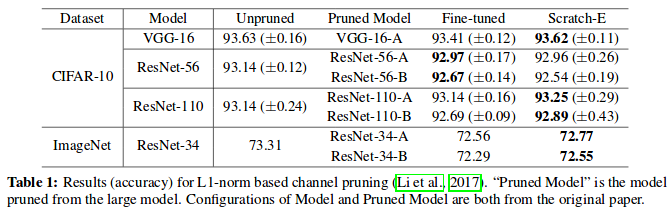
L1 norm based pruning
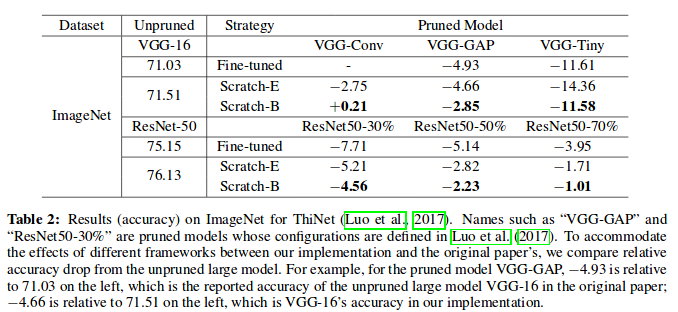
ThiNet
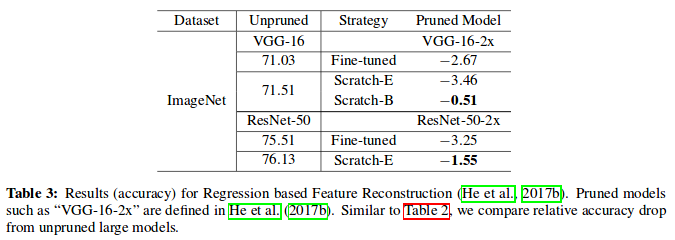
Regression based Feature Reconstruction
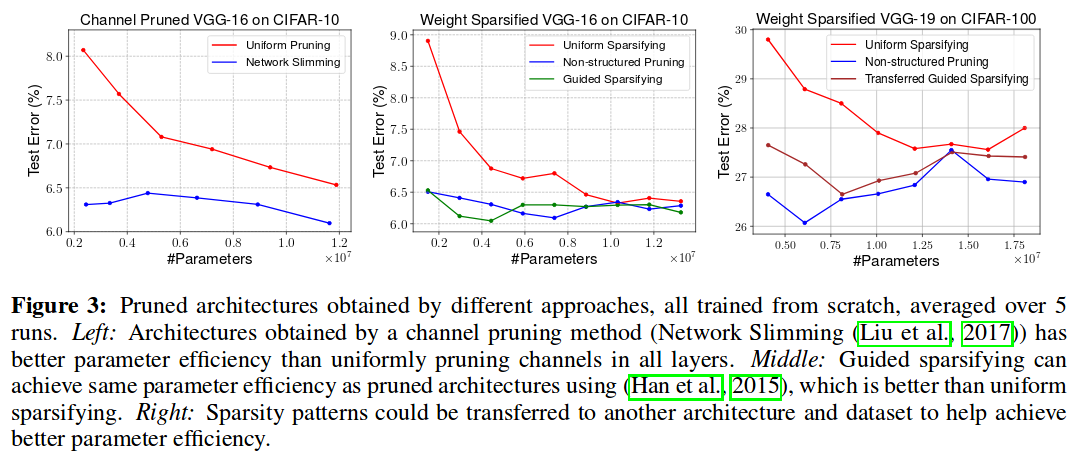
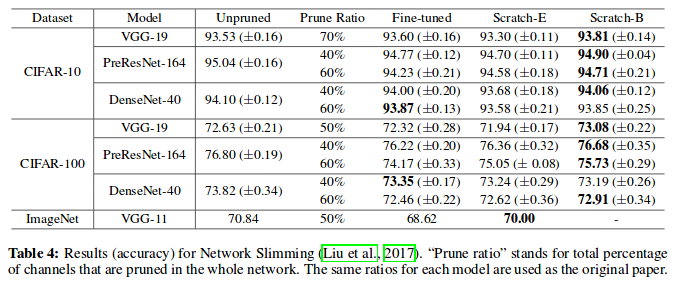
Network Slimming
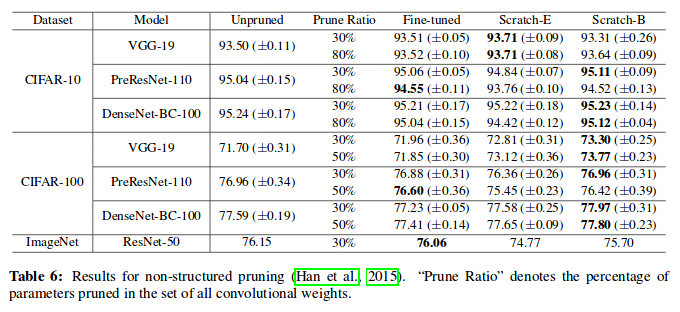
Non-structured pruning
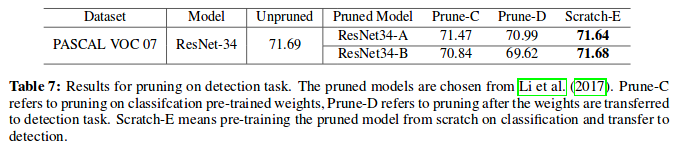
Pruning for detection task
Pruning is good for architecture search