Super-resolution of Sentinel-2 images: Learning a globally applicable deep neural network
A big problem in deep-learning is the lack of data. In remote sensing, in addition to the fact that the publicly available data is rare, most of it do not have the same resolution.
Several papers show a real use of the hyperspectral in deep learning. Unfortunately, except for small hyperspectral resolution, used for land or aerial imaging, the resolution for those hyperspectral sensors are generally worse than that of RGB sensor.
This paper shows a super-resolution method to put the hyperspectral band with a larger GSD to the same resolution than that of the RGB image. Those images can be used to better analyse data and thus improve prediction accuracy.
The data used for creating the method came from the constelation of Sentinel-2 (S2), two identical satellites with the same sensors at 180 degrees of each other. The sensor gives 13 bands with different information and resolution.

The big avantage from S2 is than they cover the entire earth and all the data are accesible for every one.
The Method
Since the resolutions are 10, 20, and 60m, and they want to generalise every band at 10m GSD, they use 2 CNNs: one to upgrade 20m images to 10m images and the other to upgrade the resolution from 60m to 10m. In that case, they do not need annotated images, but they use the real value for a 20m and 60m resolution for ground truth and they downsample the training images to 40 and 360m as follow.
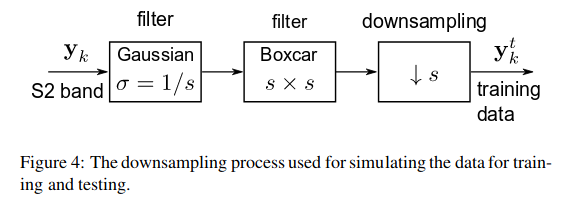
In this way, they can train the two networks, to be able to learn 2x and 6x super resolutions. At the end they will use those networks to predict on 10m GSD with no way to quantify the results’ accuracy.
This super-resolution algorithm optimised for (but conceptually not limited to) S2, with the following characteristics:
- significantly higher accuracy of all super-resolved bands
- better preservation of spectral characteristics
- favourable computational speed when run on modern GPUs
- global applicability for S2 data without retraining, according to our (necessarily limited) tests
- generic end-to-end system that can, if desired, be retrained for specific geographical locations and land-covers, simply by running additional training iterations
- free, publicly available source code and pre-trained network weights, enabling out-of-the-box super-resolution of S2 data.
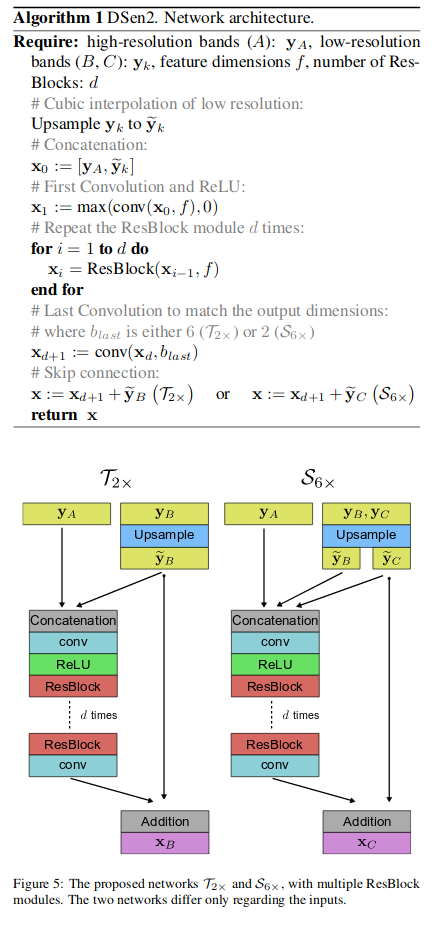
They obtain 2 networks, DSen2 and VDSen2, the difference is the \(d\) and \(f\) that will be 6, 128 for the DSen2 and 32, 256 for VDSen2.
Results