Large Scale GAN Training for High Fidelity Natural Image Synthesis
As we know, GANs are really tricky to train and they often produces abnormal results. The authors propose to fix all of this with the following contributions:
- Use bigger and better model
- Better sampling from the latent space

Unfortunately, it will be incredibly hard to reproduce because it requires :
- JFT-300M one of the biggest dataset ever made
- 128-512 TPU v3 cores
Bigger models
They start with a default SA-GAN, they swap the BatchNorm with class-conditional BatchNorm and provide class information to the discriminator with projection. They also find that GANs work best with big batch size even if the model will collapse sooner. Finally, they boosted the number of channels everywhere by a factor of 2.
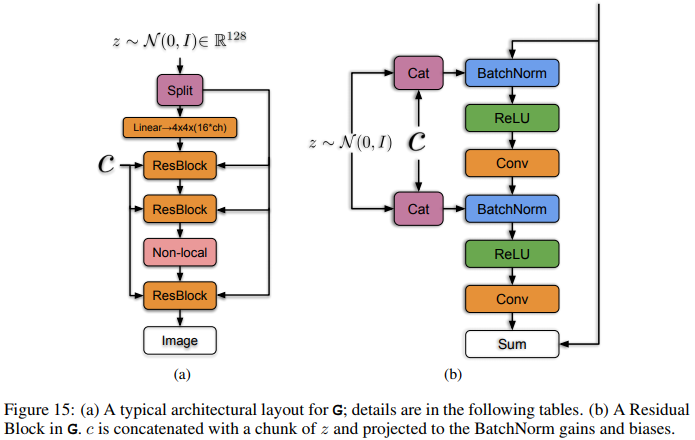
Better sampling
To avoid large values in the latent space, they used a truncated normal where values outside a range are resampled. This range can now act as a tradeoff between diversity and fidelity
They did find that some models wouldn’t work with the truncated normal, so they added a new regularization to force G to be smooth. This regularizer aims to minimize the pairwise cosine similarity but does not constrain the norm of the filters.
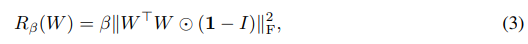
This is highly similar to the orthogonality regularizer.
