Towards the first adversarially robust neural network model on MNIST
Adversarial attacks received a great amount of attention in the past year. Despite this, all methods can still be easily fooled by most attacks, even on MNIST. The authors propose a new method which is less accurate, but more robust.
They argue that current methods are fooled because we don’t validate the prediction from the network. To do so, they compare the input image to a generated image.
To generate those images, they train a VAE for each class, using the standard training method of VAEs. They then only keep the decoder part and are performing exact inference during test time.
Using gradient descent, they can optimize in the latent space to generate the closest sample to the input image. (See fig. 1)
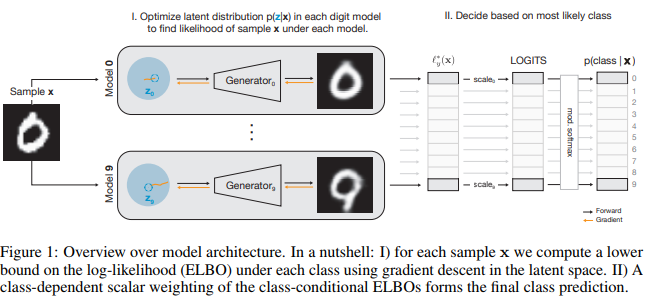
When the optimization completes, we get a likelihood for each class. We can then apply a softmax to get the actual prediction.
Their method is the most robust to every attack so far available. (fig. 3)

While their method is not scalable, it’s a good first step toward robust NN.