PackNet: Adding Multiple Tasks to a Single Network by Iterative Pruning
Background
The goal of this method is to solve multiple image classification tasks with a single network. Previous approches tried to avoid catastrophic forgetting by using proxy losses. While training subsequent tasks, “Learning without Forgetting” (LwF) tried to preserve activations, and “Elastic Weight Consolidation” (EWC) tried to preserve the value of the weights.
Approach
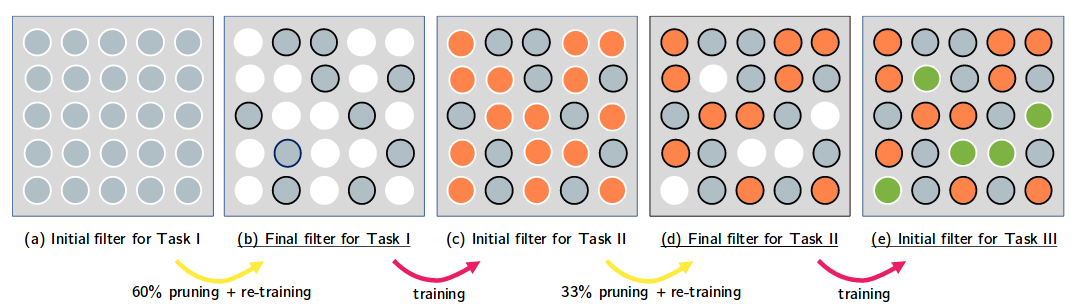
The suggested approach uses pruning to “pack” multiple models into one network:
- Train task 1
- Prune network and freeze sparsity pattern
- Fine-tune task 1
- Train task 2 with the “empty” neurons
- Prune the neurons of task 2 (and freeze sparsity)
- Fine-tune task 2
- etc…
Pruning method
- Weight magnitude selection
- Select 50% or 75% of smallest weights for removal
- Unstructured sparsity
Inference
- Predict on a single task at once
- Apply task masks before inference
- Simultaneous inference requires filter-wise sparsity, they say, and performs worse
Experimental results
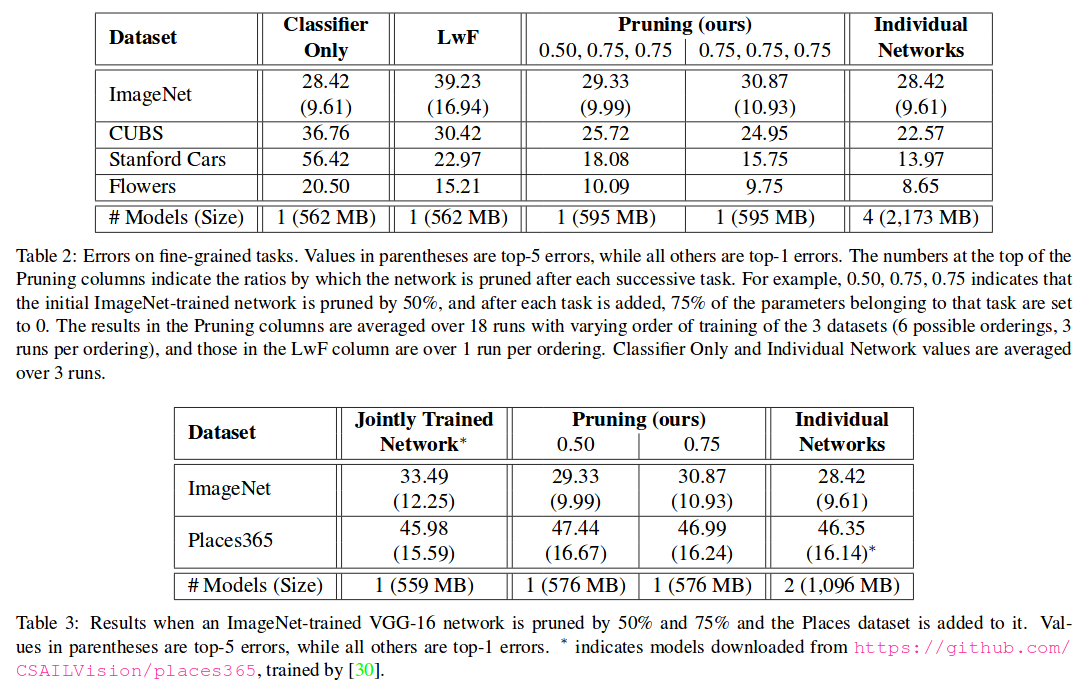
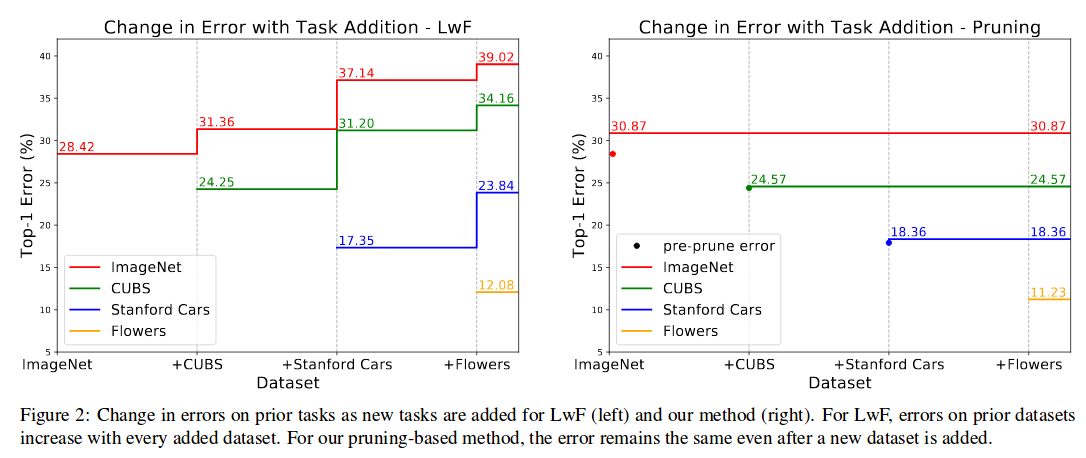
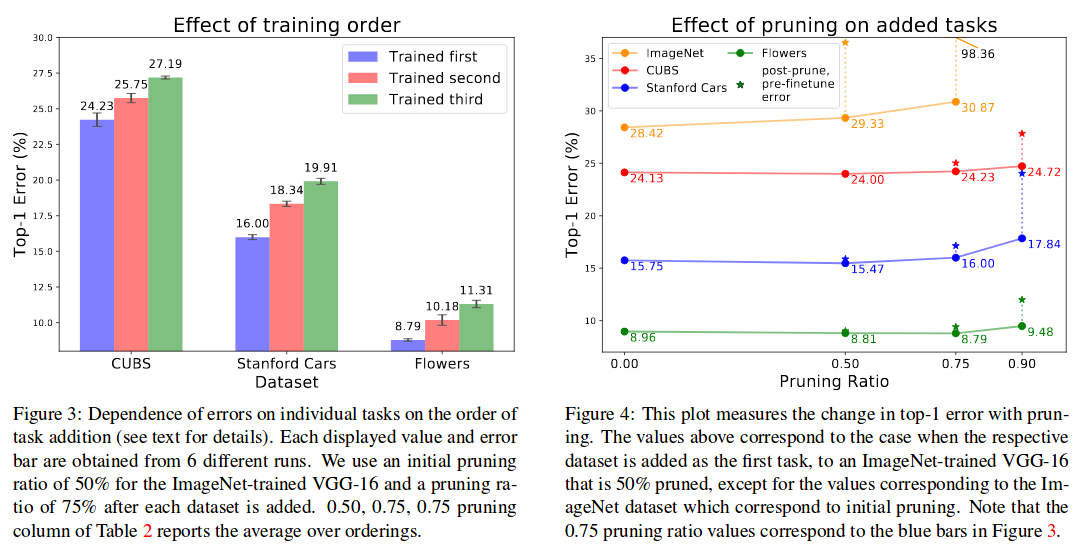
They are better than previous methods, and only slightly worse than using an individual network per task (which is nice). They confirm that their method works with VGG16 (with Batch Norm), ResNet and DenseNet (see table 4 in paper).