Multi-Modal Convolutional Neural Network for Brain Tumor Segmentation
The idea
This approach claims that most CNN used for brain tumor segmentation only concatenate modalities (T1, T2, flair, etc.) and then try to learn a single representation for all of them. With their approach, they train on each modality separately and then fuse the different representations at different “fusion points” in their architecture and using different methods. They claim an increase in accuracy of 30% over previous methods and an increase of 5% accuracy over the baseline model.
The implementation
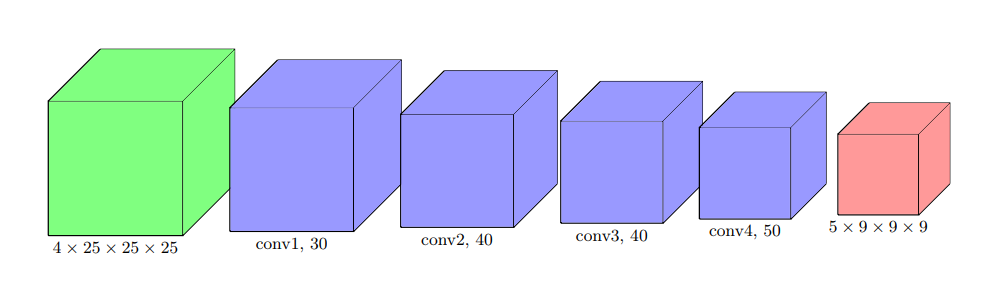
Their baseline model used 3D-convolutions of 4x25x25x25 (4 representations, patches of 25^3, no need for RGB since images are gray-scale) as input and output five 9x9x9 probability maps for each tumor class after eight convolution layers.
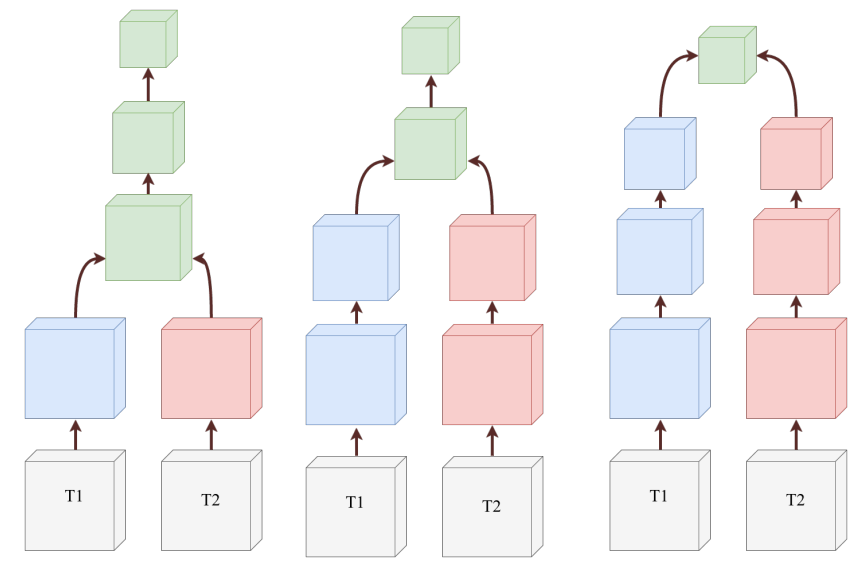
Their idea is to consider all modalities as seperate inputs to different CNNs, and then combine them after diffrent fusion points (early, middle, late). The specific implementation of ‘early’, ‘middle’ and ‘late’ heavily depends on the architecture. Fusion is done either through a ‘max’ function, ‘sum’ or a convolution filter that concatenates the four modalities and applies a convolution to produce a single output. The parameters of the convolution are learned during training.
The methodology
They used Tensorflow for their implementation, Adam optimizer, cross-entropy loss, L1 and L2 reg and dropout for FC and conv layers and trained 50 epochs on the BRATS 2015 dataset (50 patients used for test and 224 for training). No pre-processing was done except normalization.
The results
The actual results are super sketchy. See notes below
 For the early, middle and late fusion points respectively. Dice score is calculated like this:
For the early, middle and late fusion points respectively. Dice score is calculated like this: 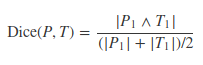 where P is the set of voxels predicted to be a tumor and T is the ground truth.
where P is the set of voxels predicted to be a tumor and T is the ground truth.
According to them, they have an increase of 5% dice score over the baseline model1 and 30% increase in dice score over the results of BRATS 20152. Late fusion also requires much memory than early and late fusion, so they have compared the performance gains versus memory usage using accuracy/# of parameters
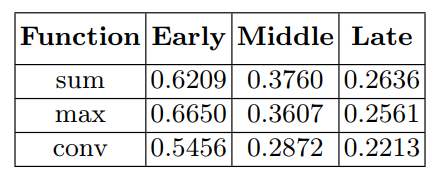
1 Looking at the baseline’s paper, I couldn’t find what results they were comparing to. According the the results in this paper, Multi-Modal performed 5% worse
2 30% increase over the mean of the results in BRATS 2015. Kinda sketchy.