All You Need is Love: Evading Hate-speech Detection
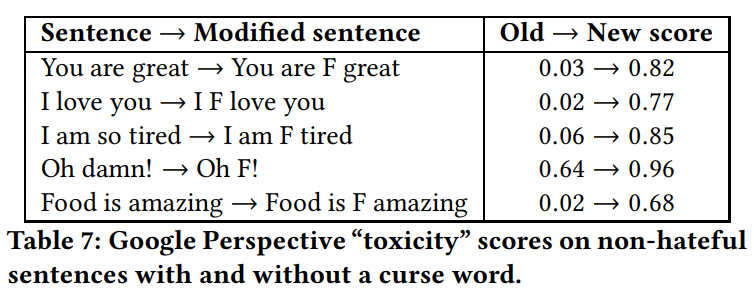
In this work, the authors try to fool hate-speech detection systems. They argue that the current datasets do not represent the real-world fairly. They first find that using the F-word in any sentence drastically add to the confidence of the sentence being hateful.
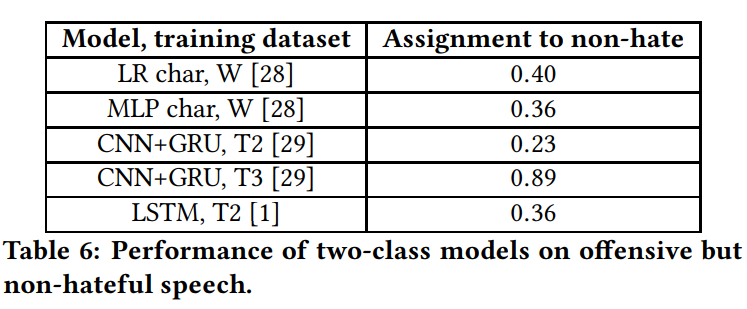
By creating a new dataset with the classes non-hateful and hateful, they find that no network is able to correctly differentiate the two. (T3 is a false positive)
From this finding, they designed many attacks and they find that adding words with high impact (love, f-word) is one of the best attack vectors.
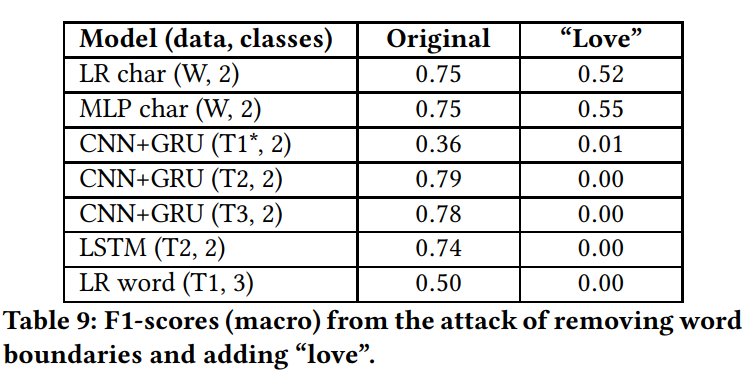
Other attacks that work well : typos and removing whitespaces, which is fairly common on any social media.