What do Deep Networks Like to See?
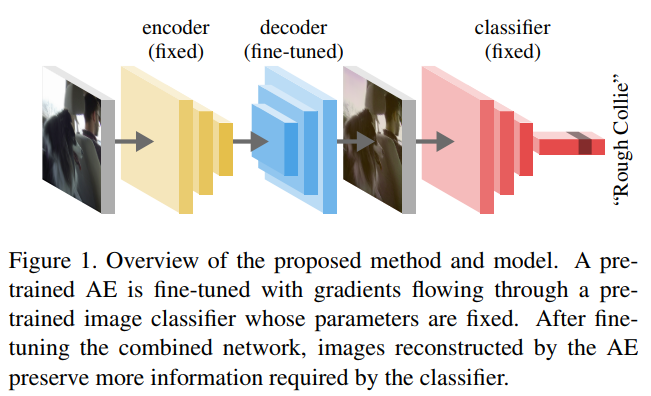
To better understand the difference between architecture, the authors propose to finetune the decoder part of an autoencoder with the gradient from different classifiers. (See fig.1)
They pretrain the autoencoder on YFCC100M which is so big that the autoencoder converge before the completion of a single epoch. Most of the results (accuracy improvement, denoising) can be attributed to the additional parameters from the autoencoder, but section 3.5 is interesting.
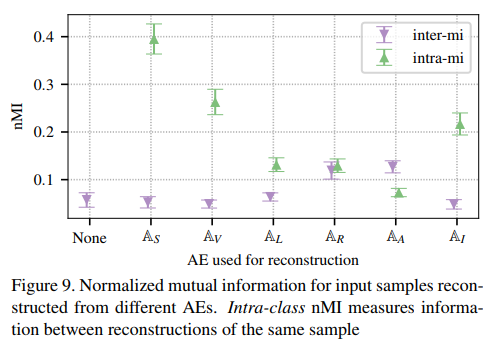
In this section, they compare the mutual information between the original input and the reconstruction with different classifiers. This is the intra-mi.
They also compare the reconstruction of different input. This is the inter-mi.
The intra-mi should be high to keep the maximum amount of information and the inter-mi should be low to differentiate inputs.
They used five types of classifiers : AlexNet (A), VGG-16 (V), Inception V3 (I), Resnet-50 (R) and LeNet-5 (L). \(A_S\) refer to the original autoencoder trained on YFCC100M. The structure of this autoencoder is similar to SegNet.
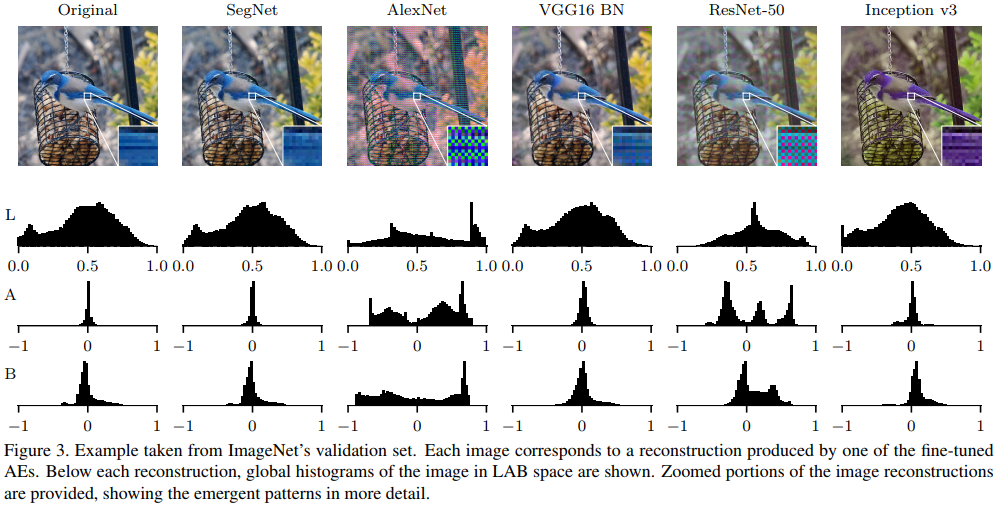
As we see, VGG-16 keeps a great amount of information while ResNet and AlexNet create similar patterns for all inputs. This can be seen in fig. 3, where they both reconstructed the image with a checkerboard effect.