CNN with Alternately Updated Clique
Inspired by ResNet and RNN, the authors present networks organised as a “clique”, a original way of connecting layers in order to optimise the information flow.
They further improve it by adding :
- a multi-scale approach
- a attention mechanism
CliqueNet
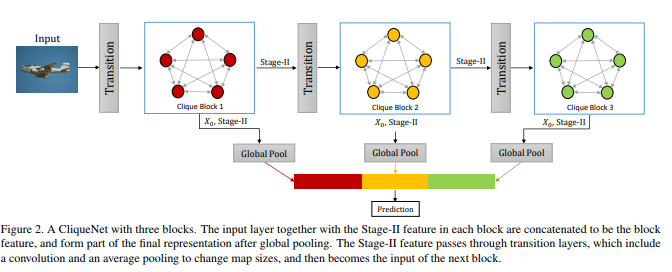
The multi-scale approach is nothing fancy : the final prediction is performed from feature maps from three cliques which operate at different scales.
The optimization of a clique is more tricky as it requires a two-step approach :
- Stage I : the layers are initialized one after the other from the previous layers (starting with only the input).
- Stage II : All layers are both inputs and outputs of the others and they are updated one at a time, alternatively.
Though it is never explicitly said, the first stage seems to go farther than initialization and that layers are first optimized in the first stage and then refined in the second.
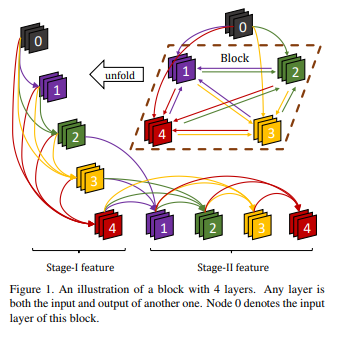
The idea is that residual connections can be extrapolated as a RNN as they give “later” layers access to “earlier” (unprocessed) information. DenseNet, which consists in aggregating outputs of all previous layers as inputs, shows a rapid growth of parameters. To alleviate this, a clique structure recycles its weights.
CliqueNet with extra-techniques
The transition can be used to provide an attention feedback from higher levels to refine lower level activations by applying binary weights to filters:
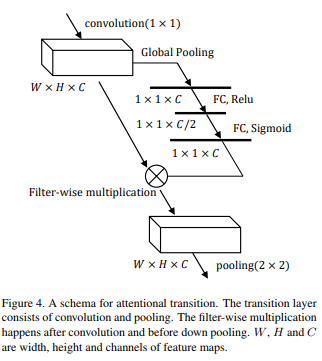
They also use 1*1 convolutions to compress the input of a given clique and reduce the number of parameters (bottleneck effect).
The feature maps from a clique are forced to be reduced by half in number (compression).
Experiments
Implementation details : They use three to four scales with cliques of 5 layers. Each layer contains 36 filters, use batchNorm and ReLu. Note : They strongly benefit from decaying the learning rate.
They apply their approach to classification problems : CIFAR 10/100, SVHN (Street View House Number) and ImageNet.
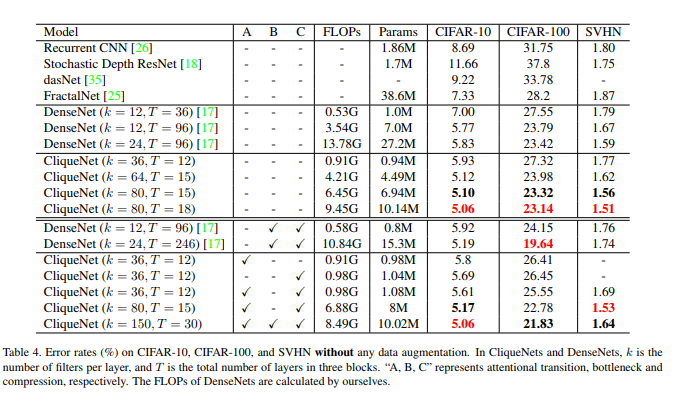
Without extra-techniques, they always outperform by a small margin DenseNet with fewer parameters and without data augmentation.
Observation : Attention and Compression always add a little something but the BottleNeck isn’t so consistent.
With extra-techniques, and CliqueNet with the highest capacity, the best scores can be obtained on all three datasets (but the comparison without extra-tech is not provided).
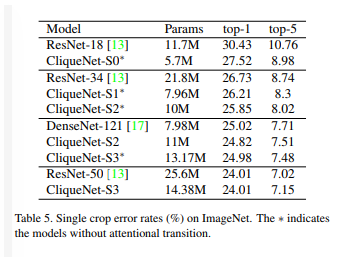
The same can be said when compared to ResNet on ImageNet.
Bonus : visualization

The second stage helps denoising the feature maps by extracting features focused on object of interests.