Functional Map of the World
Dataset
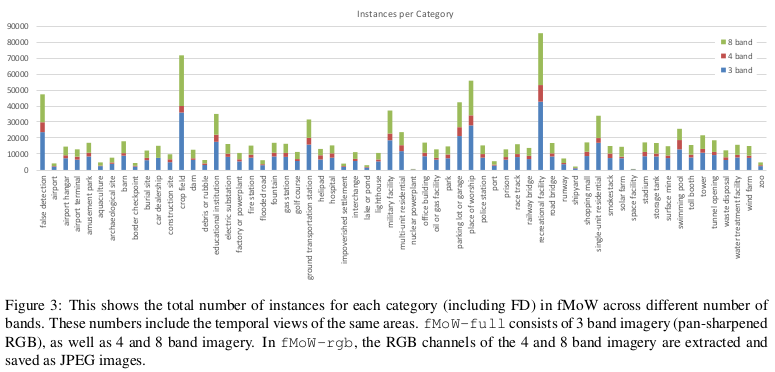
Over 1 million images from over 200 countries. Each image provides at least one bounding box annotation containing one of 63 categories.
the dataset includes:
- UTM Zone (zone of projection)
- Timestamp (year, month, day, hour, minute, second, and day of the week UTC)
- GSD (Ground sample distance)
- Angles (the sensor is imaging the ground, as well as the angular location)
- Image+box sizes
3 types of images: 8/4/3 bands, 4 and 8 are RGB with multispectral images (MSI). All images are 256x256 with roughly 30cm resolution.
Meaning of the paper
The paper presents an analysis of the dataset along with baseline approaches to show relation about metadata and temporal views.
Approaches:
- LSTM-M An LSTM architecture trained using temporal sequences of metadata features.
- CNN-I A standard CNN approach using only images, where DenseNet is fine-tuned after ImageNet. Softmax outputs are summed over each temporal view, after which an argmax is used to make the final prediction. The CNN is trained on all images across all temporal sequences of train + val.
- CNN-IM A similar approach to CNN-I, but with metadata features concatenated to the features of DenseNet before the fully connected layers.
- LSTM-I An LSTM architecture trained using features extracted from CNN-I.
- LSTM-IM An LSTM architecture trained using features extracted from CNN-IM.

Results
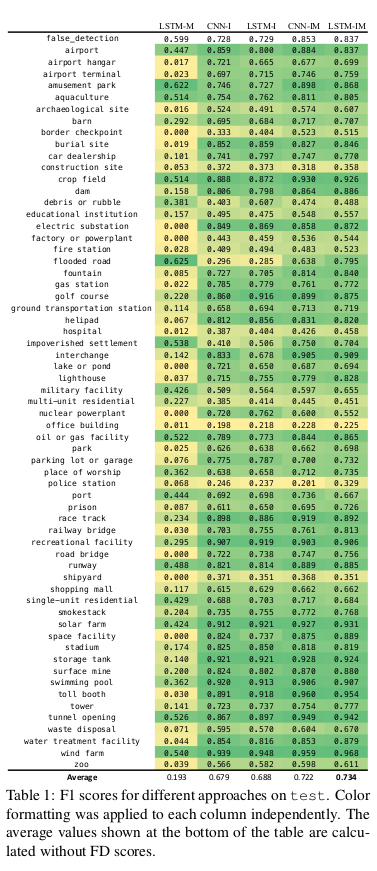
That temporal changes may not be particularly important for several of the categories. CNN-I and CNN-IM are already reasoning about temporal information while making predictions by summing the softmax outputs over each temporal view. The results for approaches using metadata are only making improvements because of bias exploitation. To show that metadata helps beyond inherent bias, they removed all instances from the test set where the metadata-only baseline (LSTM-M) is able to predict some of the category well.