Adaptive Neural Trees
In this article, the authors present a novel way to mix decision tree models and Deep Learning that allows to build the tree from scratch while learning features and routing data to accelerate inference (the best of the two worlds).
Neural Networks versus Decision Trees
Neural Networks :
- don’t require feature engineering
- can be trained with stochastic optimizers
Decision Trees:
- don’t require a predefinite architecture (they “grow” and scale to the problem needs by clustering the data)
- Inference is conditional : it doesn’t involve the whole model
The idea is take the best of the two.
ANTs
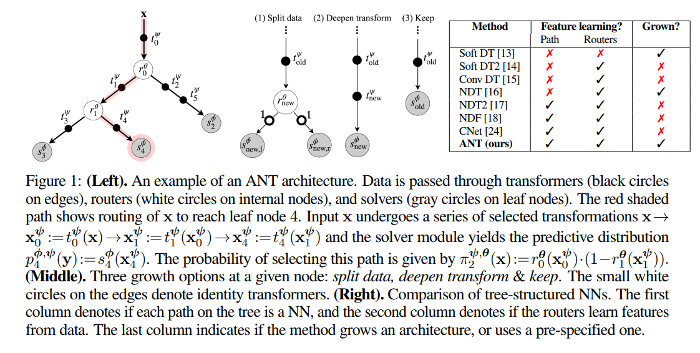
In an ANT, computational paths and routing decisions are represented by (small) NNs with predetermined architecture. Exemple :
- router: \(1*conv5-40 + POOLING + 2 * FC\)
- transformer: \(1*conv5-40\)
- solver: \(FC\)
The local optimization algorithm that determines the nature of a node uses back propagation and a classification loss (Negative log-likelihood).

Once every path ends by a leaf, the tree is fully grown and a refinement step is applied to globally optimize the model and correct to some extend sub-optimal choices :
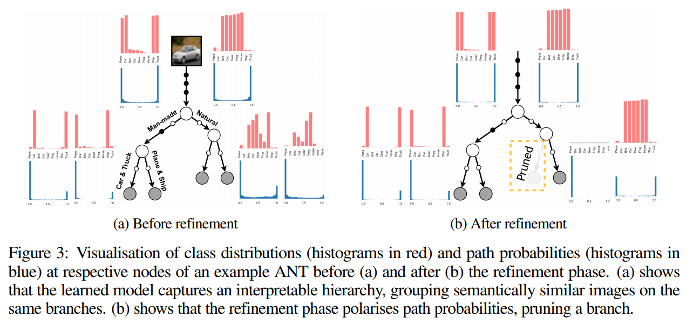
The whole process takes less than 2 hours on a single GPU since only one tree is built.
Experiments
They conduct several experiments to show the consistency of their model. For instance, here is how their model reacts to the addition of training data according to the number of parameters in the primitive module (A > B > C) and compared to all-CNN :
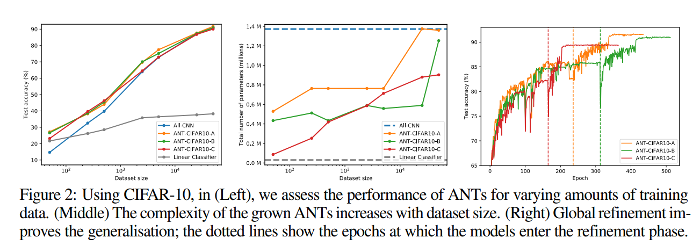
They apply this on MNIST and CIFAR-10, and mainly compare to similar hybrid methods, along with classical RF and CNN (LeNet5 and all-CNN). They beat them with a lot less parameters involved overall and at test time.
Here are the results :
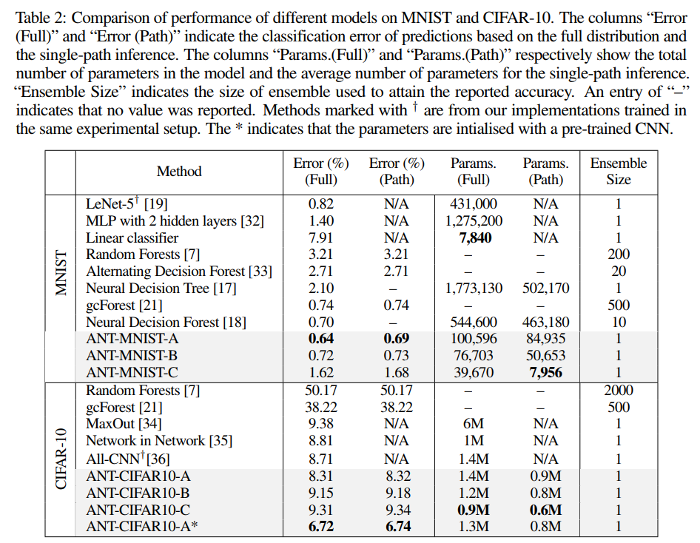
They note that using transfer-learning helped boost their performance significantly, which suggests that their optimisation method could (should) be further improved.