Rethinking the Faster R-CNN Architecture for Temporal Action Localization
TAL-Net is an extension of Faster R-CNN to perform action recognition on sequences. This work proposes two main contributions:
- Variable receptive field
- Late feature fusion
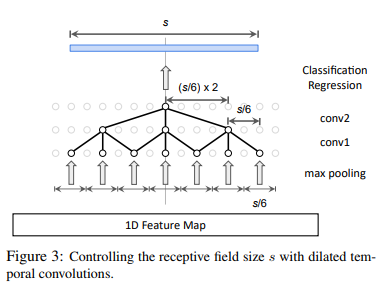
Variable receptive field
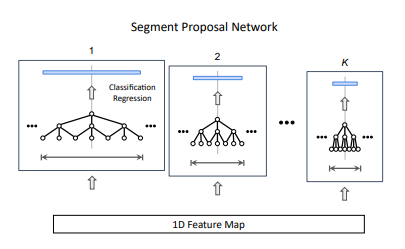
To better handle long sequences, they reuse the system of anchor but for different temporal spans. They have \(K\) 3D CNN for each temporal anchor. To get a matching dimension, they use a variable number of dilated 3D CNNs. At the end, there is a classification task on which anchor to select.
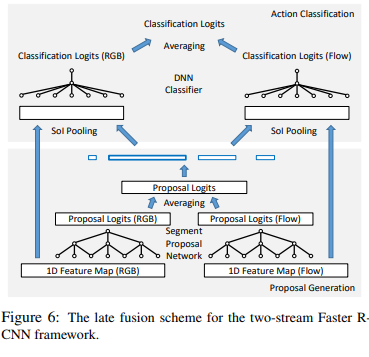
Late feature fusion
Most action recognition techniques use the RGB image and the optical flow as their input. Previous methods concatenated those streams where this method uses two distinct models where each model handles one stream before merging them.
Results
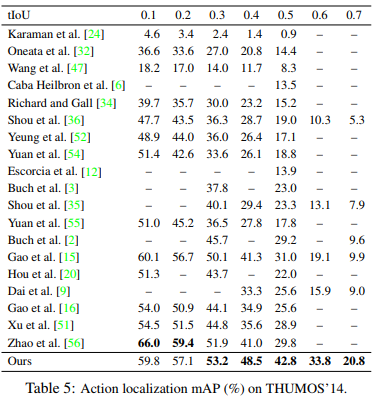
They test their method on THUMOS14 and test multiple temporal IoUs (tIoUs). On tIoU = 0.5, they are better than the previous SotA by 11.8%.