MaskLab: Instance Segmentation by Refining Object Detection with Semantic and Direction Features
Description
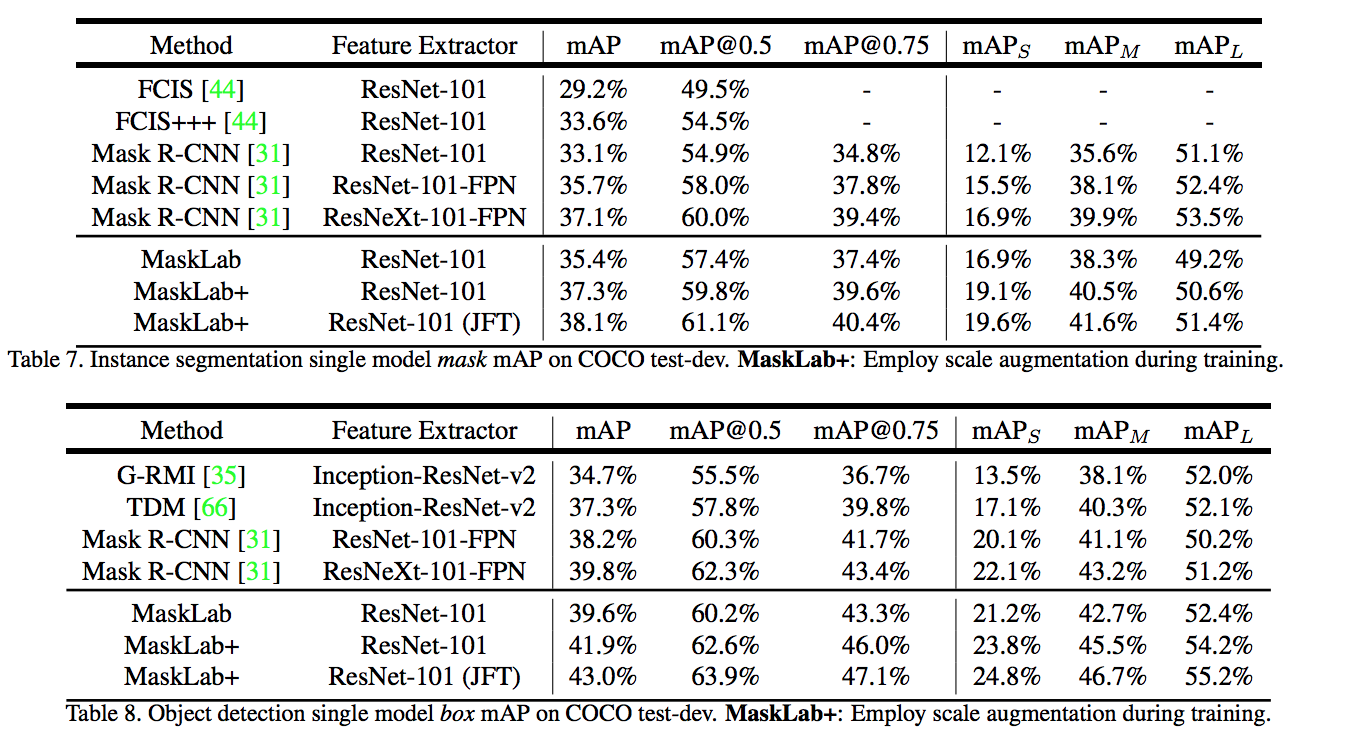
The authors present a model, called MaskLab, which produces three outputs: box detection, semantic segmentation, and direction prediction. The box detection provides accurate localization of object instances and is built on top of Faster-RCNN object detector on ResNet model.
The semantic segmentation, encoding the pixel-wise classification information to distinguish between objects of different semantic classes. However, they applied a direction prediction to separate object instances of the same semantic label.
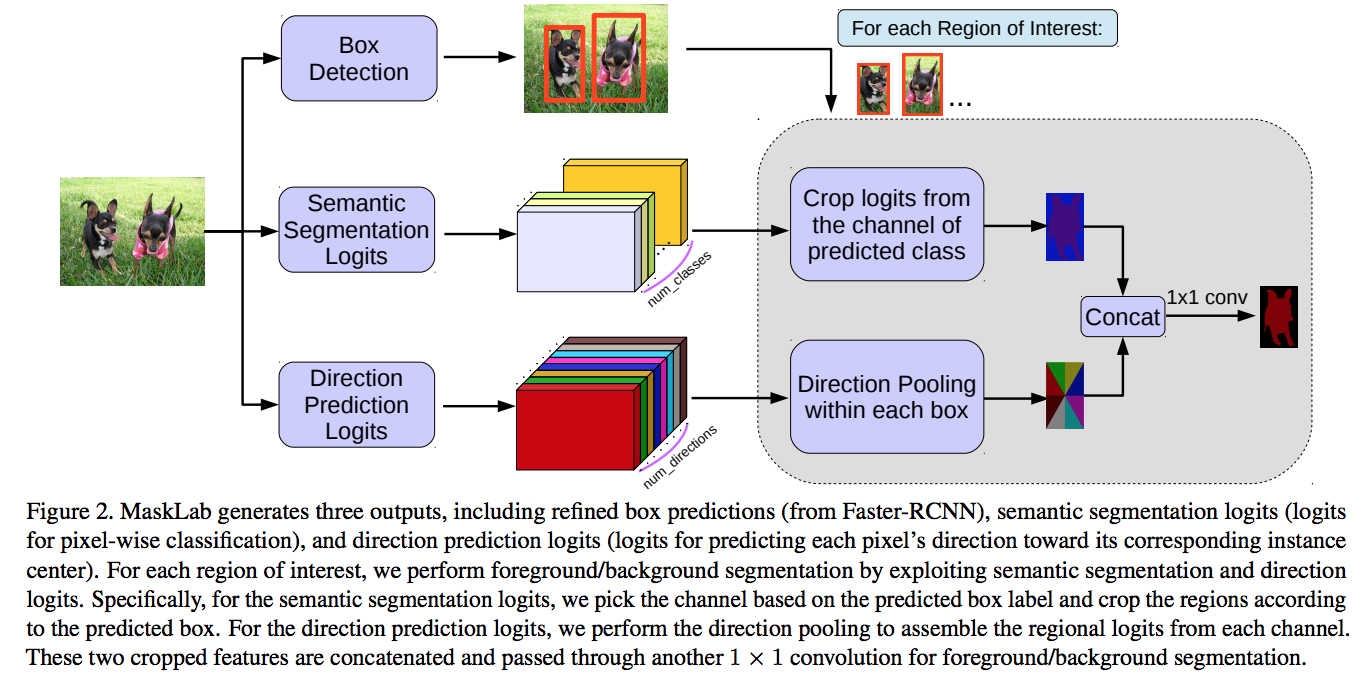
Given each predicted box from a pretraind Faster-RCNN model, they perform foreground/background segmentation by exploiting segmentation logits and direction prediction logits which is used to predict each pixel’s direction towards its corresponding instance center.
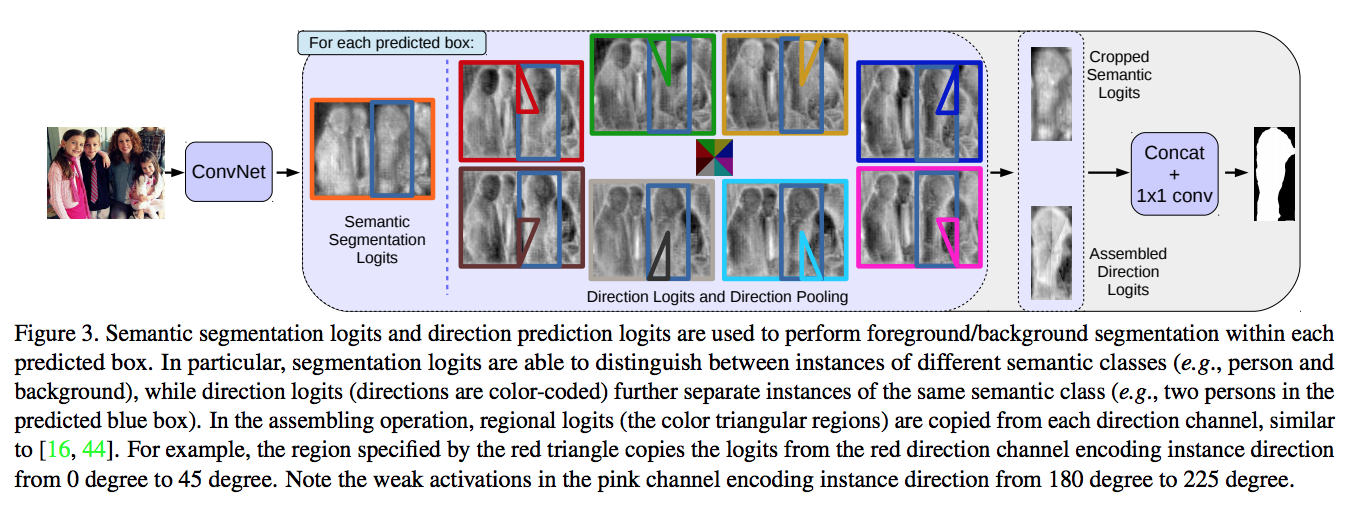
Given the predicted boxes and labels from the box prediction branch, first, select the channel from the semantic segmentation logits, and crop the regions base on corresponding predicted box, then applied direction pooling to get scores on each pixel to classified relative object instance to the center pixel.
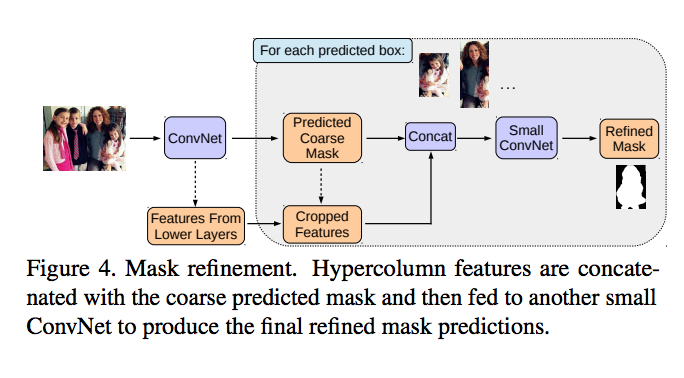
Finally, refine the predicted masks from semantic and direction features with features from lower layers of ResNet-101, by three extra convolutional layers in order to predict the final mask.
Results