Autofocus layer
The authors present a new kind of layer called autofocus that learns the best effective receptive field by selecting via an attention mechanism the optimal dilation rate for convolutions.
Autofocus
The idea is to learn the appropriate scales for identifying the different objects of interest in an image because anatomical objects can either have variable size (bones, tumors, organs…) or be characterized by their size.
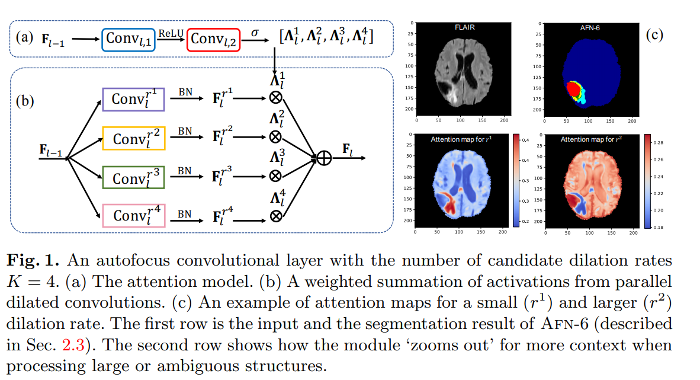
The attention network in a) produces normalized K activations for each voxel, K being the number of scales considered. The attention weights are shared across all channels of a same scale.
Also, the dilated convolutions share the same weights to make features scale-invariant. That way, each parallel filter seeks patterns with similar overall appearance but of different sizes.
Experiments
They gradually replace classical convolutions of Deep Medic upper scale branch with their autofocus layer to see the impact. Dilation rates are 2, 6, 10 and 14.
They apply this on multi-organ and brain segmentations:
- Two datasets of pelvic CT scans, one used for train and the other for test
- BRATS 2015 (brain MRI)
Here are the results :
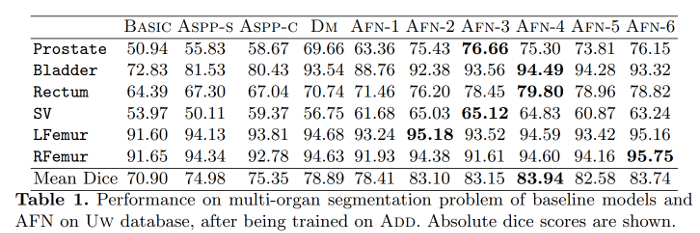
Performances are already improved with only one autofocus layer and it surpasses ASSP which corresponds to the concatenation of all the dilated convolutions. Converting more layers in autofocus tends to improve performances.
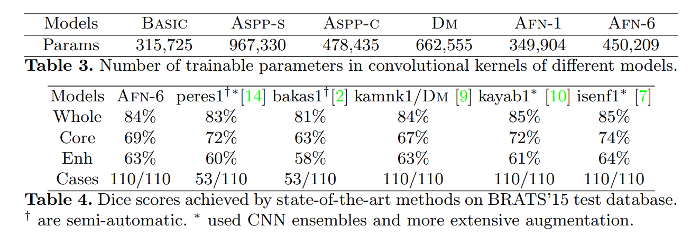
Performances are on par with the top challengers. The pipelines of 10 and 7 used ensemble models and data augmentation so the authors defend the capacity of their model to be both competitive and simple.
Source code and pretrained models: GitHub for autofocus