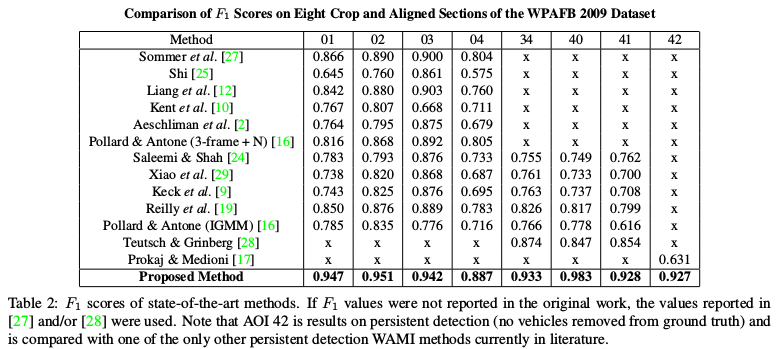
ClusterNet: Detecting Small Objects in Large Scenes by Exploiting Spatio-Temporal Information
Contribution
- Thier method utilizes both spatial and temporal information from a set of video frames to locate multiple objects simultaneously in WAMI (wide area motion imagery).
- This approach removes the need for computing background subtracted images, thus reducing the computational burden and the effect of errors in frame registration.
- The two-stage network shows the potential reduce the large search space in WAMI data with a minimal effect on accuracy.
- The proposed method can detect completely stationary vehicles in WAMI.
- The method also outperforms the state-of-the-art in WAMI in an F1 score for moving object detection and a 50% improvement for stationary vehicles, in addition of reducing the average error distance of true positive detections from the previous state-of-the-art 5.5 pixels to roughly 2 pixels.
Ideas
The proposed work to generates all object proposals simultaneously using a multiframe in previous papers, two-stage CNN for videos in WAMI in a more computationally efficient manner than background subtraction or sliding-windows, effectively combining both spatial and temporal information in a deep-learning-based algorithm.
ClusterNet & FoveaNet: Two-Stage CNN
They propose a new region proposal network which combines spatial and temporal information within a deep CNN to propose object locations. In Faster R-CNN, each 3 × 3 region of the output map of the RPN proposes nine possible objects, the network generalizes this to propose regions of objects of interest (ROOBI) containing varying amounts of objects, from a single object to potentially over 300 objects, for each 4 × 4 region of the output map of the RPN.
Following the focus on the second stage of the network on each proposed ROOBI to predict the location of all object(s) simultaneously, again combining spatial and temporal information.
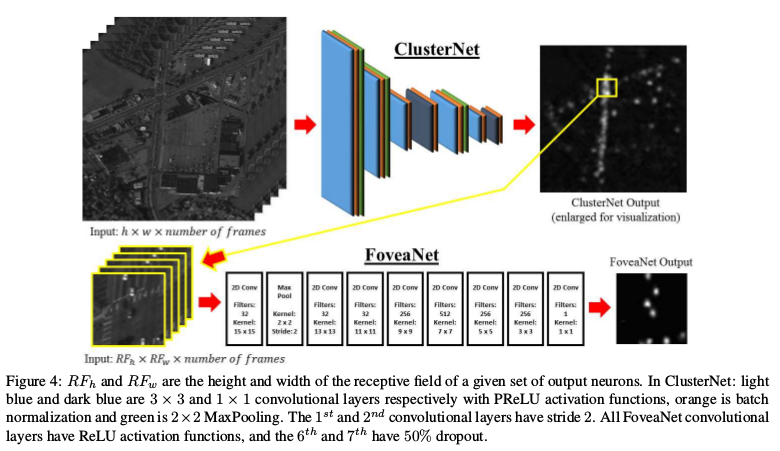
The effect is ClusterNet allows ignoring large regions of the search space while focusing a small high-resolution fovea centralis over regions which contain at least one to several hundred vehicles, illustrated below.
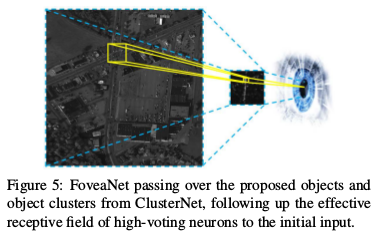
FoveaNet then predicts the location all of the vehicles within that region to a high degree of accuracy for the given time frame of interest.
Results
AOIs 01−04: 2278×2278 pixels, covering different types of surroundings and varying levels of traffic.
AOI 34 is 4260 × 2604.
AOI 40 is 3265 × 2542.
AOI 41 is 3207 × 2892.
And AOI 42 is simply a sub-region of AOI 41 but was included to test the method against the one proposed by Prokaj et al. on persistent detections where slowing and stopped vehicles were not removed from the ground truth, even though Prokaj et al. uses tracking methods to maintain detections.