Domain Shift for Semantic Segmentation
The authors propose an approach based on GANs to close the performance gap due to domain shift when applying a network learnt on synthetic data to real images.
Training scheme
More specifically, they address Unsupervised Domain Adaptation, when the data is composed of two sets : the source domain - for which we possess segmentation maps - and the target domain - that we would like to segment. This could eventually be used to create ground truth for unlabeled datasets.
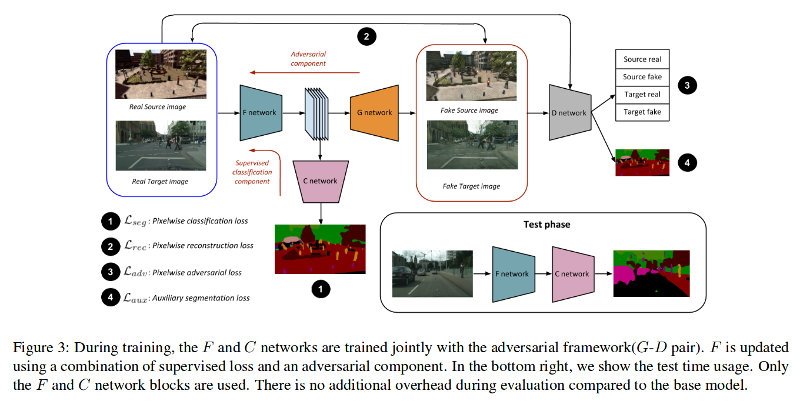
The idea is to bring the embeddings closer in the learned space to align source and target domains and even generalize to unseen domains. The features become more and more domain invariant as the generation quality gradually improves :
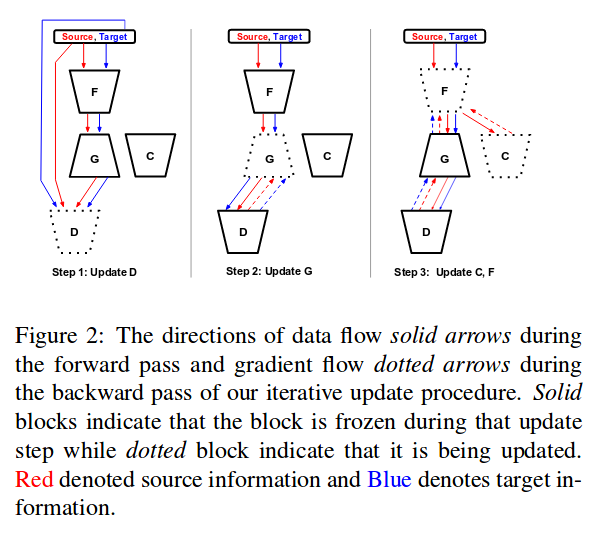
Experiments
They use networks based on the FCN-8s architecture. The discriminator is not a binary classifier as it also tries to identify datasets. It also generates a segmentation map providing an auxiliary loss.
They apply this on : annotated synthetic data : SYNTHIA (9400 images of a virtual city) , GTA5 (24966 images from the game) real data : CITYSCAPES (5000 urban street images from a moving vehicle - 2975 for training and 1595 for testing)
Here are the results on the 16 / 19 shared classes :
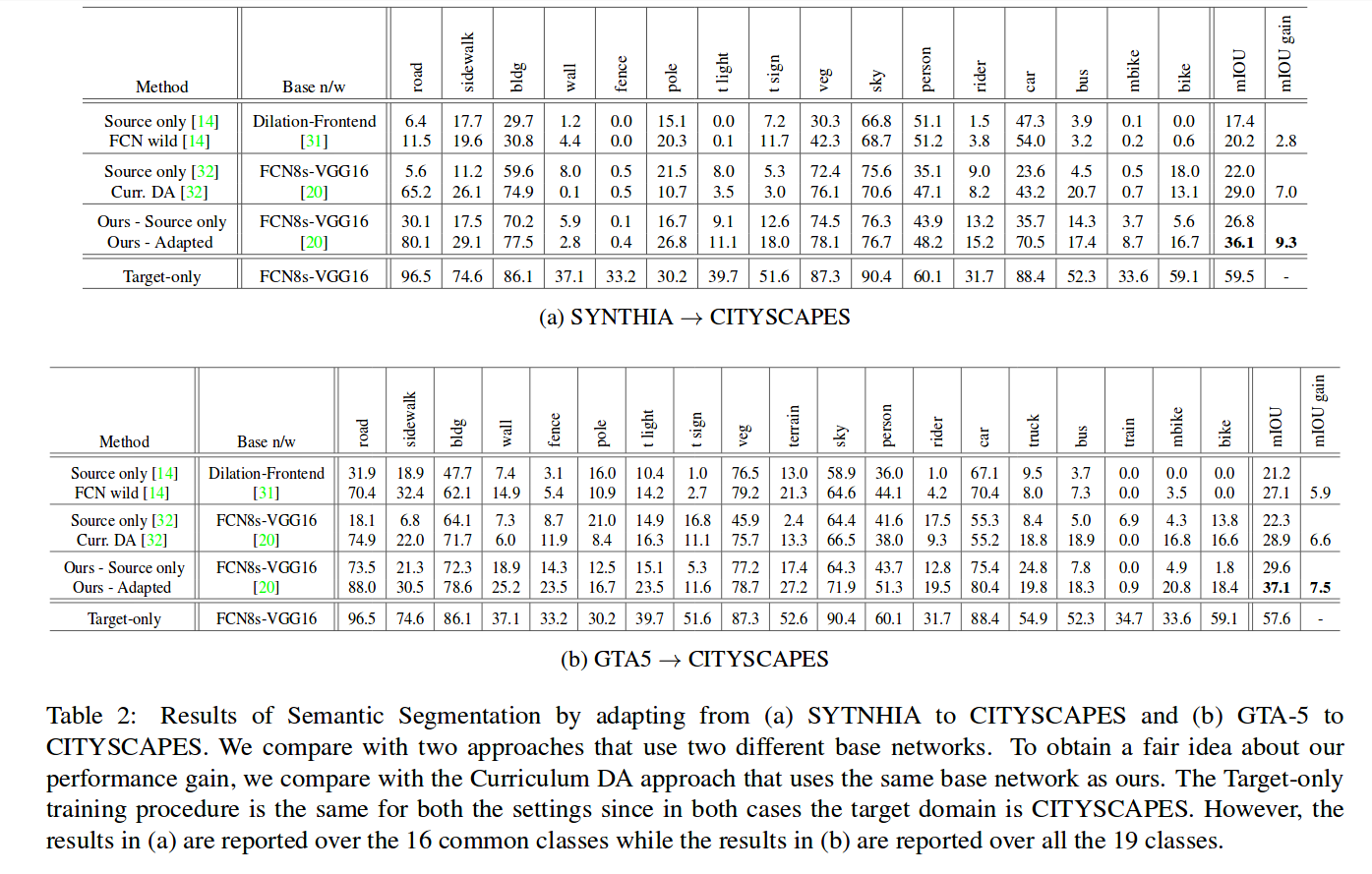
For each experiment, the supervision by a generative network improved results. They also show that each component of their final loss is beneficial and that the improvement is consistent with image size.