Learning Longer-term Dependencies in RNNs with Auxiliary Losses
TL;DR: For a sequence classification task using an RNN, adding small reconstruction/prediction tasks throughout the sequence reduces the need for full BPTT and increases performance. Even when using only the auxiliary loss (no supervised loss backprop in the LSTM), results are “good” (40% accuracy on CIFAR-10).
Summary
- Unsupervised auxiliary loss based on reconstruction/prediction that can be used for classification tasks
- Use the RNN representation to either reconstruct previous events or predict next events in a sequence
- Improves over full BPTT in performance and scalability: all gradients are truncated (auxiliary and supervised)
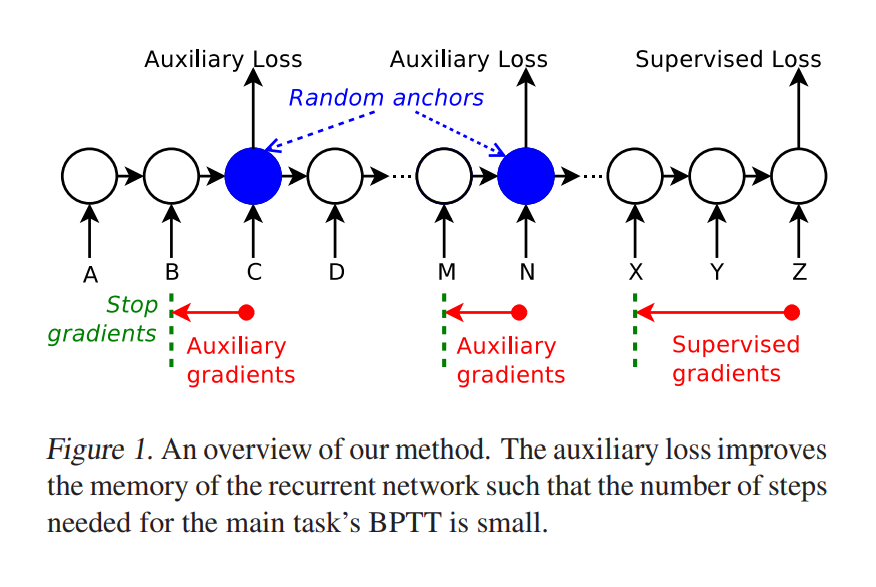
Auxiliary loss
2 models (or auxiliary losses) are defined:
1) Past sub-sequence reconstruction (r-LSTM)
2) Next sub-sequence prediction (p-LSTM)
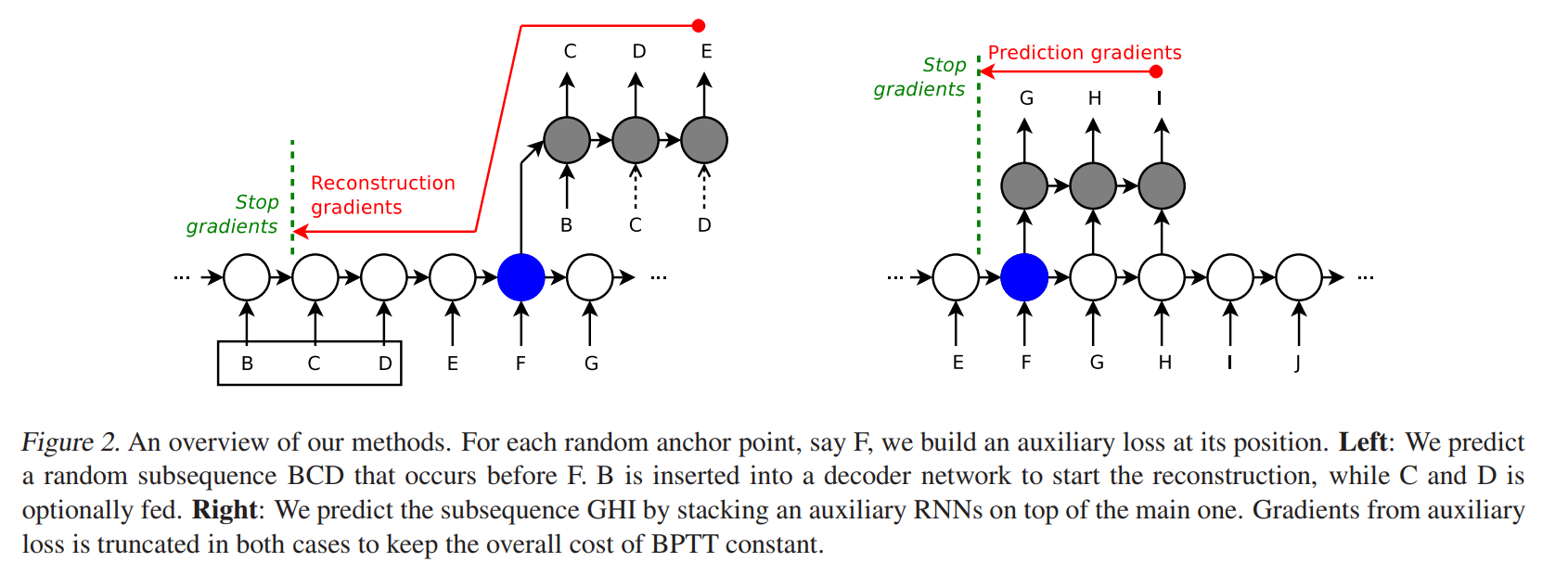
Procedure
- Anchor points are chosen randomly in the sequence
-
At each anchor point, apply the auxiliary loss
- Pretraining: Auxiliary loss only
- Training: Loss = L_{supervised} + L_{auxiliary}
Model
Classification:
- Input embedding (128) -> 1-layer LSTM (128)
- Last LSTM hidden state (128) -> 2-layer FFNN (256, 256, N_CLASSES)
Auxiliary models (reconstruction/prediction):
- 2-layer LSTM (256, 256) -> 2-layer FFNN (256, 256, N_CHANNELS)
- LSTM bottom layer initialized with main LSTM state; top layer zero-initialized
Gradient truncation:
- Gradients are truncated to 300 for both supervised and auxiliary losses
Experiments
- In most experiments, only one anchor point is used, with a sub-sequence of 600 elements
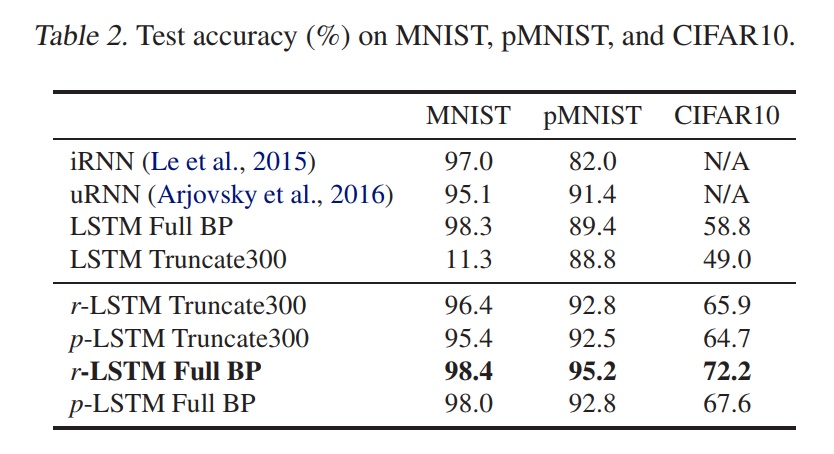
- MNIST/CIFAR-10:
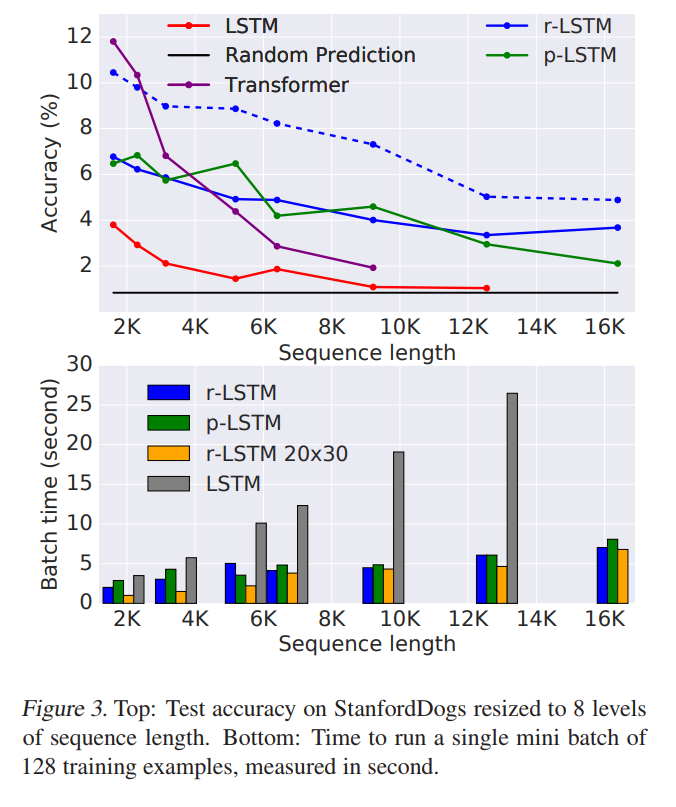
- StanfordDogs: All models have 100 epochs of training, + 20 pretraining epochs for r-LSTM and p-LSTM
- Accuracy is not the main goal, only robustness to sequence length
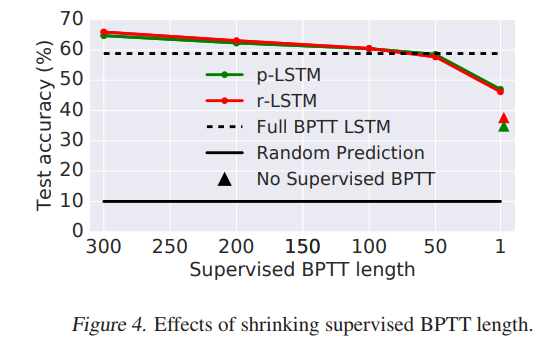
- Shrinking BPTT length on CIFAR-10:
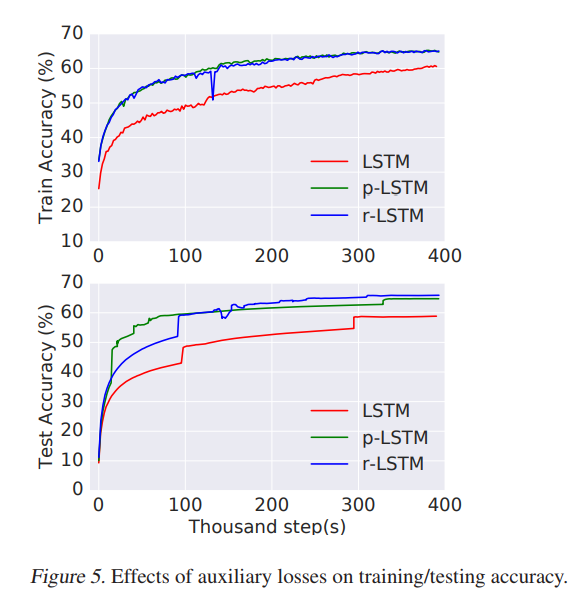
- Training/testing curves:
Notes
- The authors never used both auxiliary losses at the same time, which would have been interesting
- No validation set is used, only a fixed number of epochs (overfitting doesn’t seem to be an issue here)
- In the results table, no std or confidence score is provided
- Many details are missing, but the idea is interesting