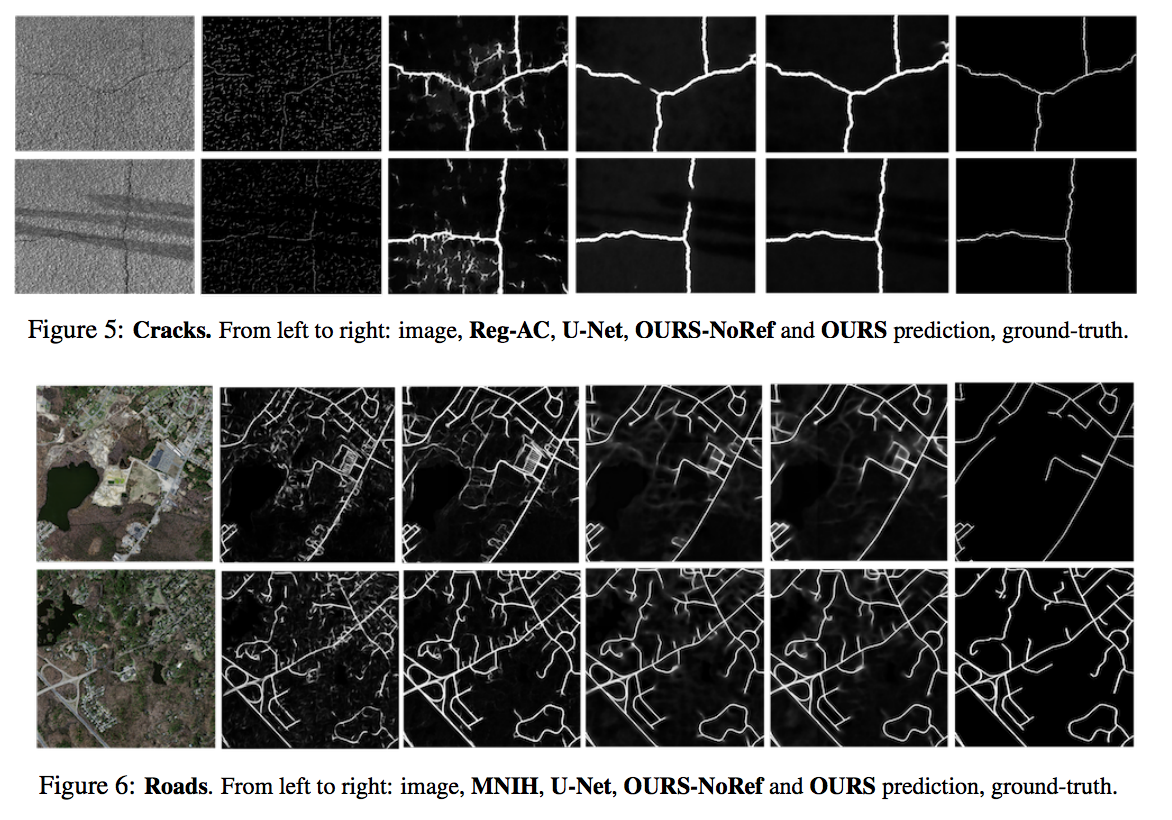
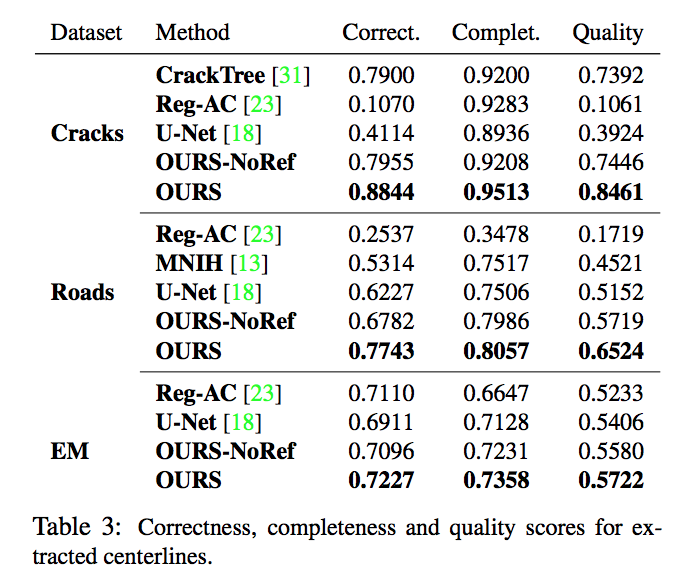
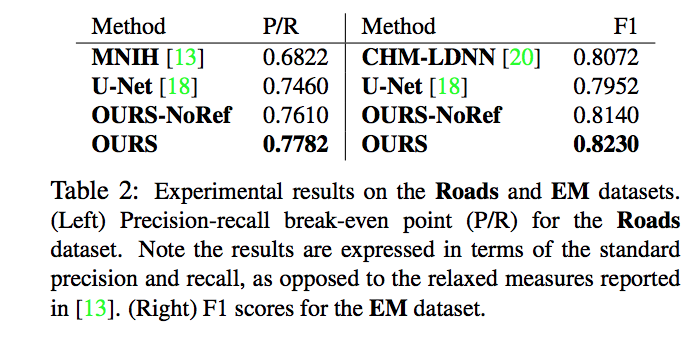
Beyond the Pixel-Wise Loss for Topology-Aware Delineation
Description
Pixel-wise loss relies on local measures and does not account for the overall geometry of curvilinear structures, so this loss treats every pixel independently and does not capture the characteristics of the topology, such as the number of connected components or number of holes. The authors proposed a penalty term to account for this higher order information.
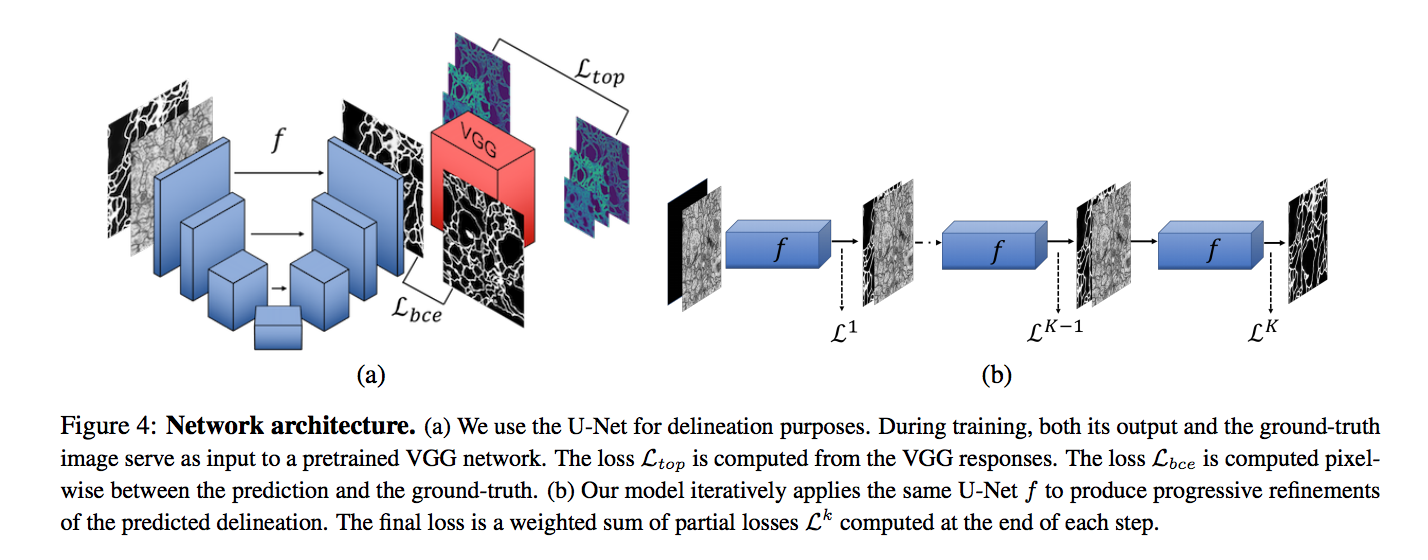
First, they used a U-net architecture to get a prediction of input data on segmentation task. Then, a VGG19 network pre-trained on ImageNet dataset used as a description of the higher-level features of the delineations which tries to minimize the differences between the higher-level visual features of the linear structures in the ground-truth and those in predicted image. The penalty is the measured distance on the m-th feature map in the n-th layer of the pretrained VGG19 network and N is the number of convolutional layers and M is number of channels in the n-th feature map.
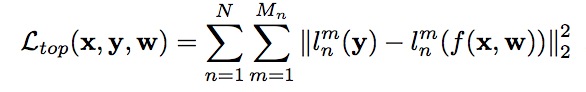
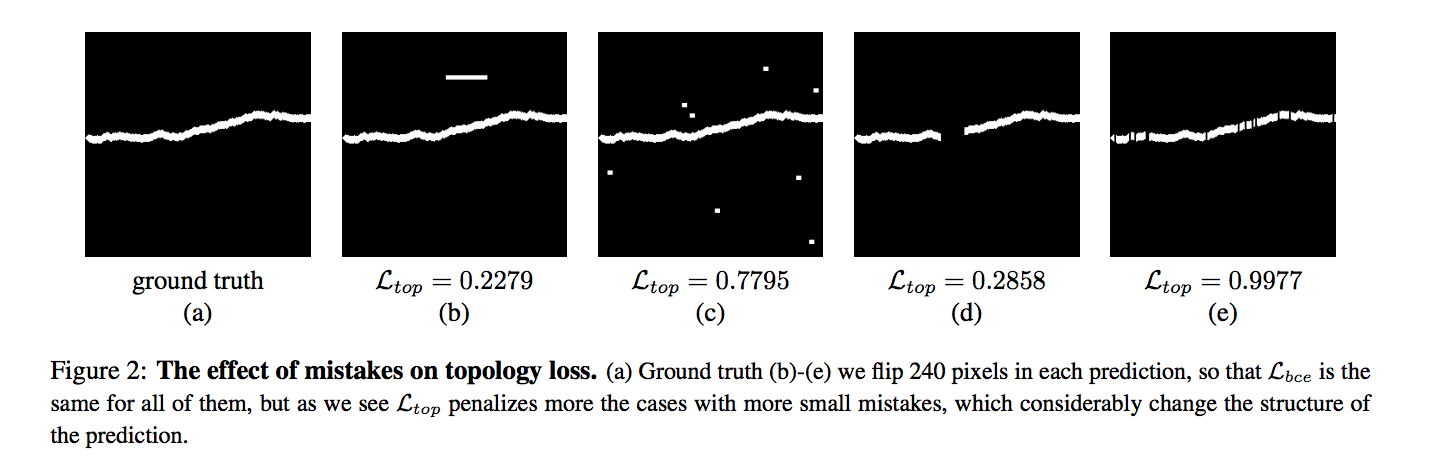
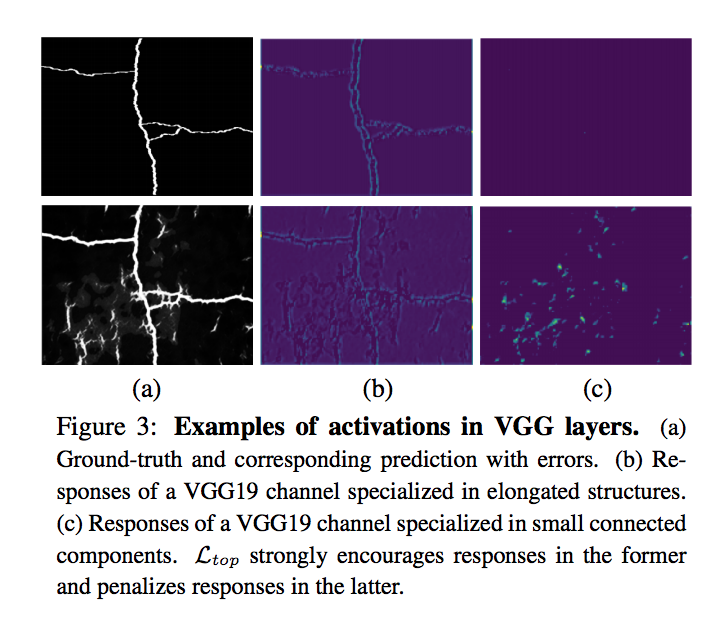
The authors claim these higher-level features include concepts such as connectivity or holes that are ignored by the simpler pixel-wise loss while their loss correctly measures the topological importance of the errors in all cases where it penalizes more the mistakes that considerably change the structure of the image and those that do not resemble linear structures as shown in below:
The authors applied an iterative refinement to remove small gaps in lines that should be uninterrupted. Therefore use the U-net and applied K times refinement of the target. Finally, when K=0, target is an empty image, and in last iteration, the input segmentation map would be our ground-truth.
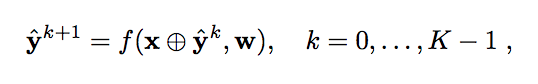
Experiments