Knowledge Distillation by On-the-Fly Native Ensemble
Description
Knowledge distillation normally works with two networks, while these days trying to bring it to a network end to end like snapshot ensemble model. In this work, The authors employ a network model with branch like Resnet(a category of two branch network where one branch is the identity mapping). In high-level layers, they design a multi-branch as ensemble models and features are largely shared across different branches in low-level layers.
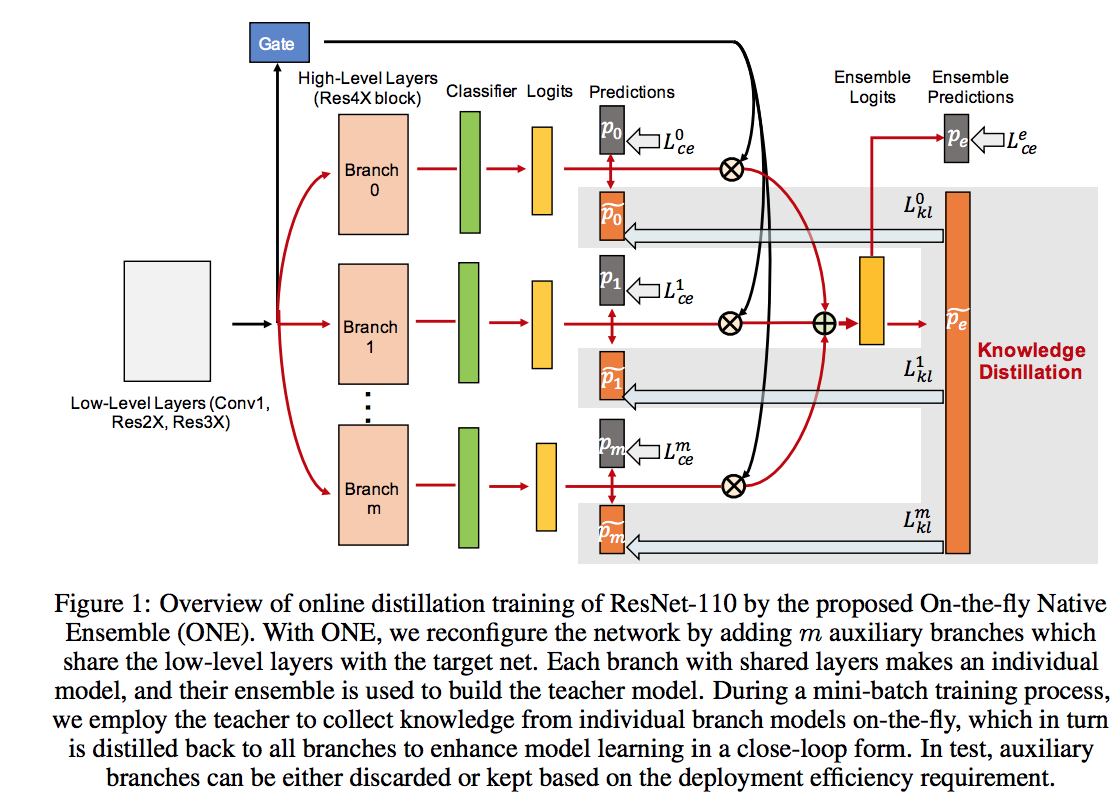
A gate component which learns to ensemble all branches to build a stronger teacher model simultaneously. Then they don’t need a pre-train teacher. The gate is constructed by one FC layer followed by batch normalization, ReLU activation, and softmax, and uses the same input features as the branches. The task of the gate is the importance score to the i-th branch’s logits and then sum over them as an ensemble model.
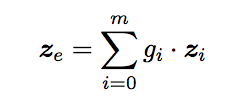
Cross-entropy loss is applied to the teacher and students. For facilitating knowledge transfer from teacher back into all branches, teacher and students logits are computed as a soft probability distribution in their predictions and then use Kullback Leibler divergence to quantify the alignment between individual branches and the teacher.
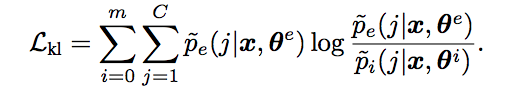
Finally loss has three components:
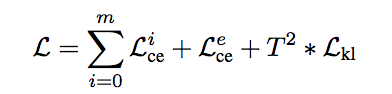
Experiments
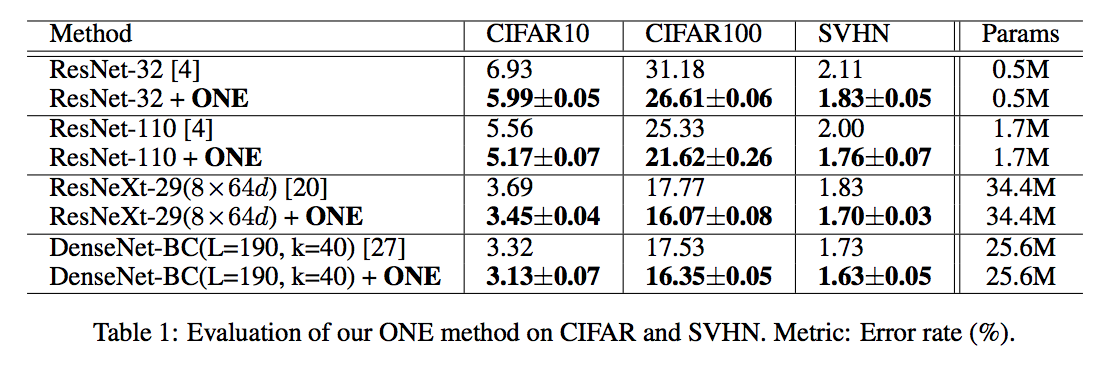
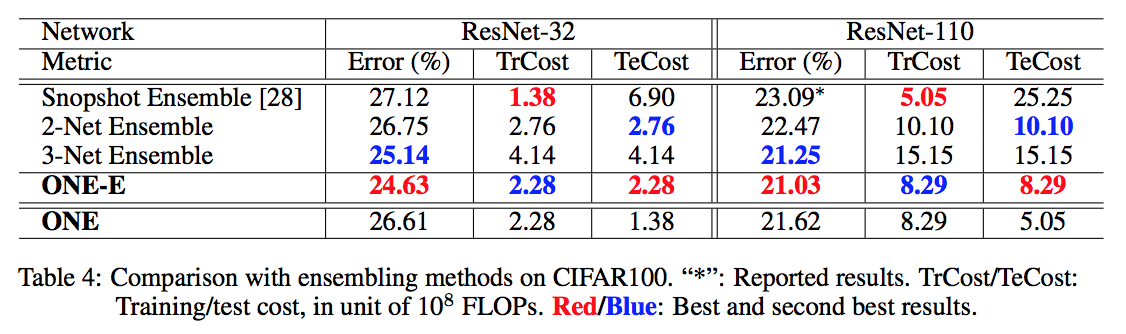
The E-one denotes an ensemble with all trained branches.