Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Introduction
One of the most highly cited attention paper. The goal is to generate a caption (sequence of words) from an image (a 2D array of pixels). As mentioned in this blog, this method generalizes over previous recurrent image-to-text methods.
Description
As shown in the following 2 figures
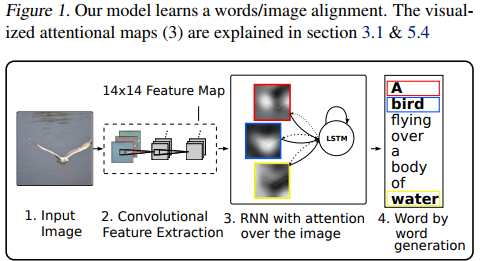
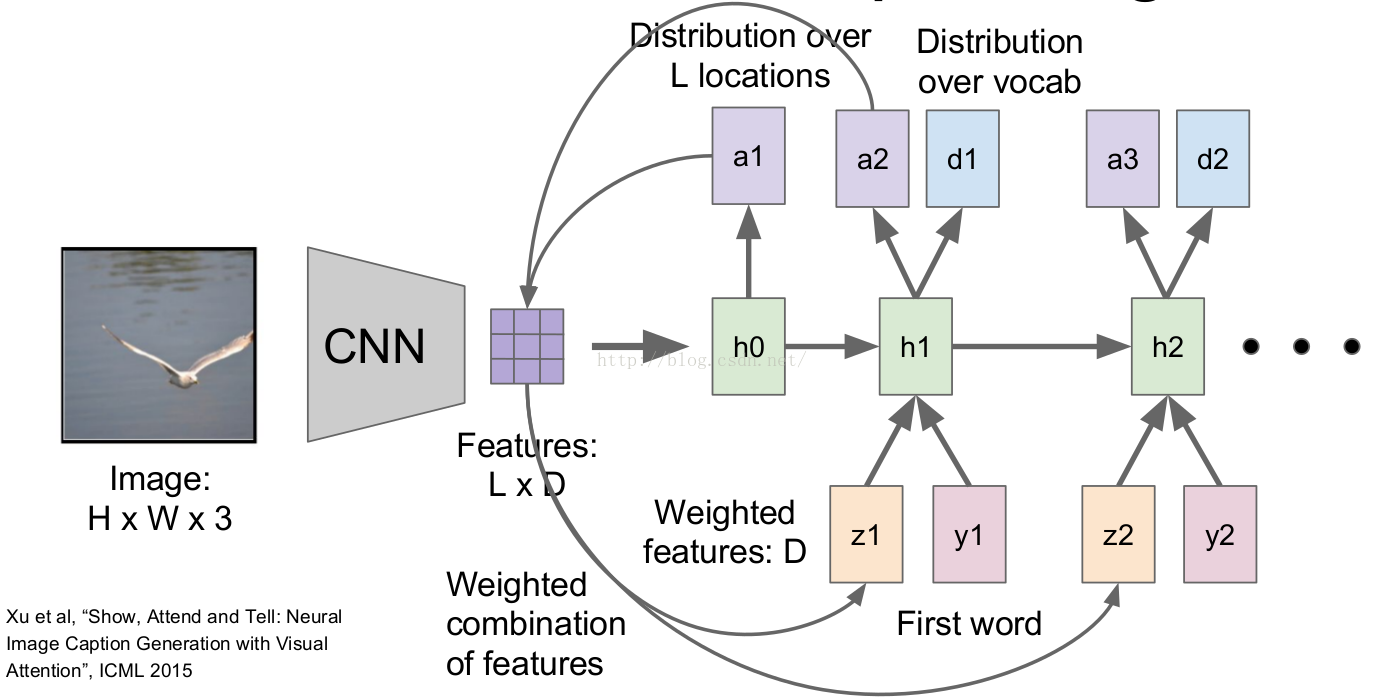
the method processes an image with a CNN. This results into a set of \(14 \times 14 \times 512\) feature maps after the fourth convolutional layer. These feature maps are then fed to an LSTM. The output of this LSTM is two fold : 1) the prediction of a word and 2) a \(14 \times 14\) mask with values between 0 and 1. This mask is called the attention associated to the next predicted word. The attention mask is then multiplied element wise to the feature maps which is fed back into the input of the LSTM. The system stops iterating when the LSTM generates the symbol “EOS” (End of Sentence).
Results
Results are cool!


Code
The code can be found here.