Indoor Scene Labeling
Description
They propose a new method called Multimodal RNNs for RGB-D scene semantic segmentation to classify image pixels given two input sources(modalities): RGB color channels and Depth maps. The model has two RNNs, one of which is assigned to learn the representations of a single input modality. To connect both RNN modalities and allow information fusion, information transfer layers is employed to select and transfer the relevant patterns from one modality to the other modality, and vice versa.
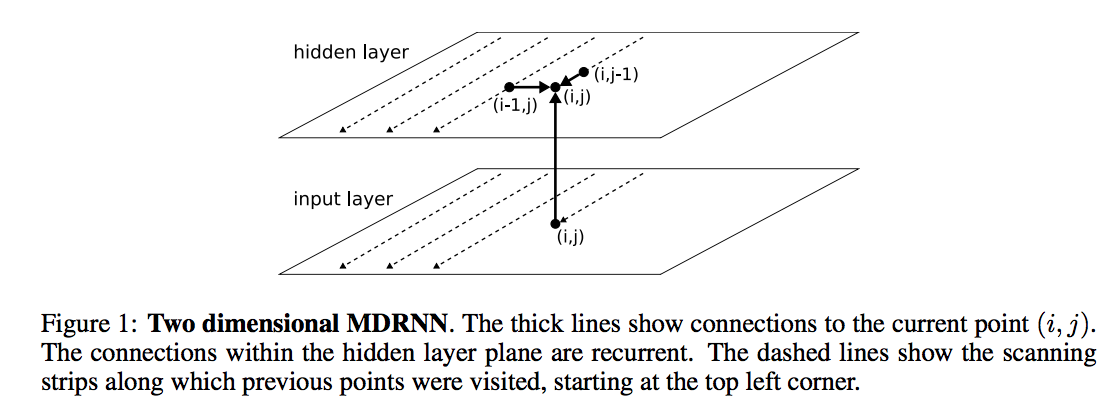
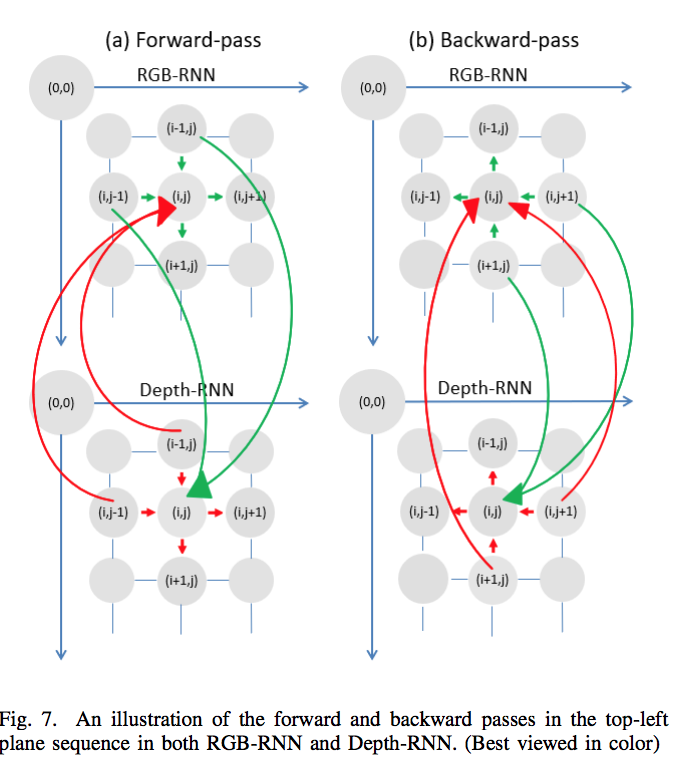
Each modality employes a multidimensional recurrent neural network. The basic idea of (MDRNNs) is to replace the single recurrent connection found in standard recurrent networks with as many connections as there are spatiotemporal dimensions in the data, so at every point, the layer has already visited the points one step back along with every dimension. The hidden activations at these previous points are fed to the current point through recurrent connections, along with the input as shown in Fig(1).
As you see, this RNN has just one direction, but we usually want surrounding context in all directions. The generalization of bidirectional networks with four hidden layer one starting in the top left and scanning down and right, one starting in the bottom left and scanning up and right,so all the hidden layers are connected to a single output layer, which therefore receives information about all surrounding context.
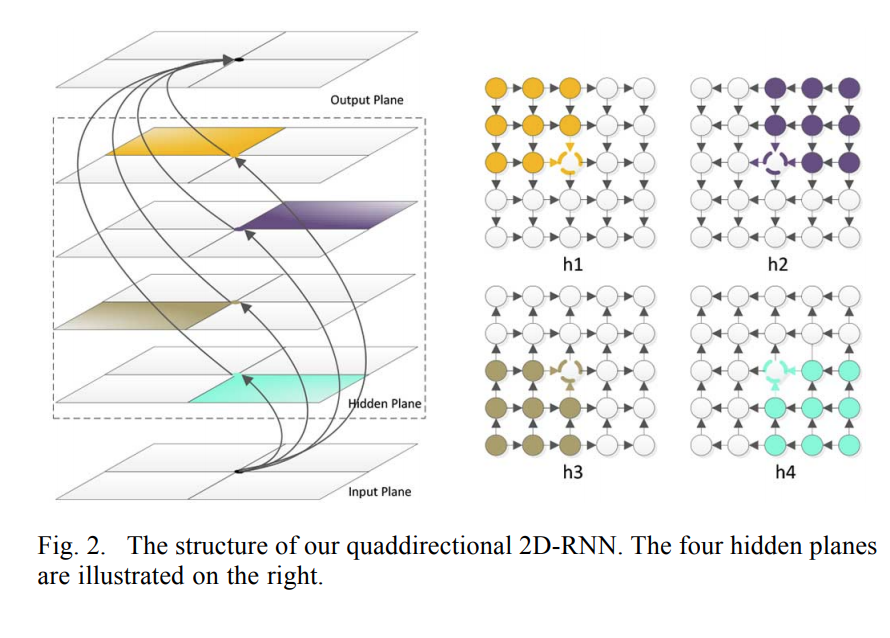
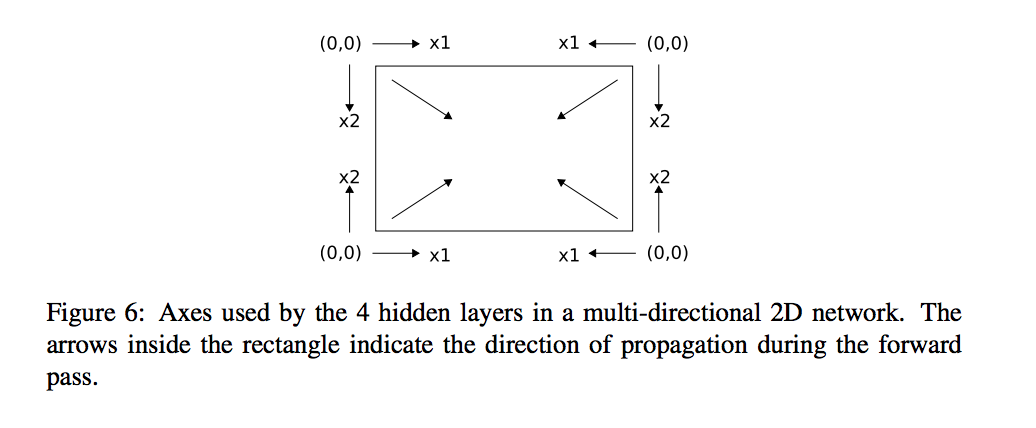
The authors, first extract multiple patches from the images and generate their corresponding convolutional feature vectors to form the input to MDRNNs model, then for each layer, transfer information from the same layer in another modality.
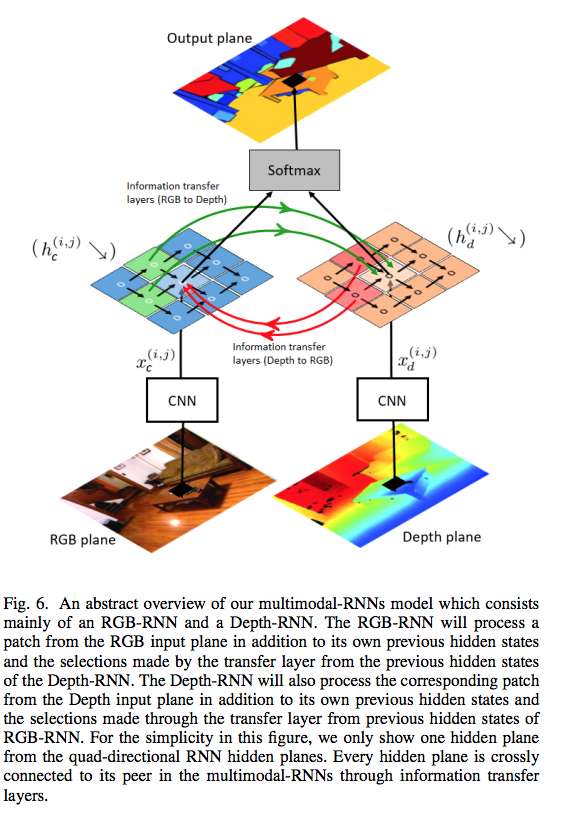
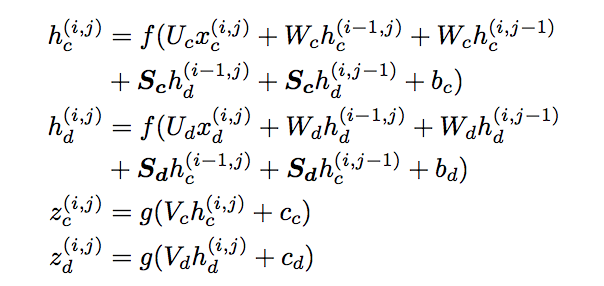
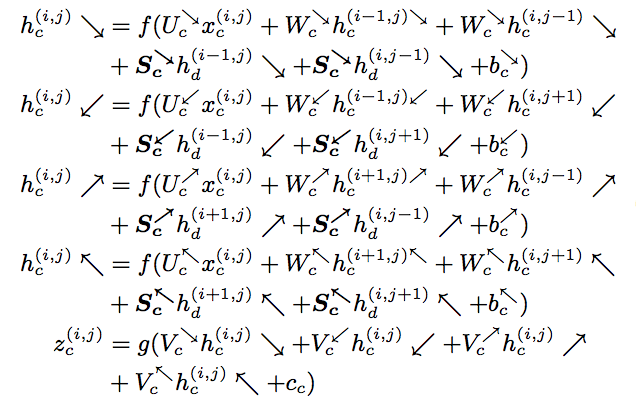
Where x is a feature vector of a certain patch at location (i,j) in RGB image (refer to c) and Depth image (refer to d) and h are hidden sets inside each RGB-RNN and Depth-RNN.
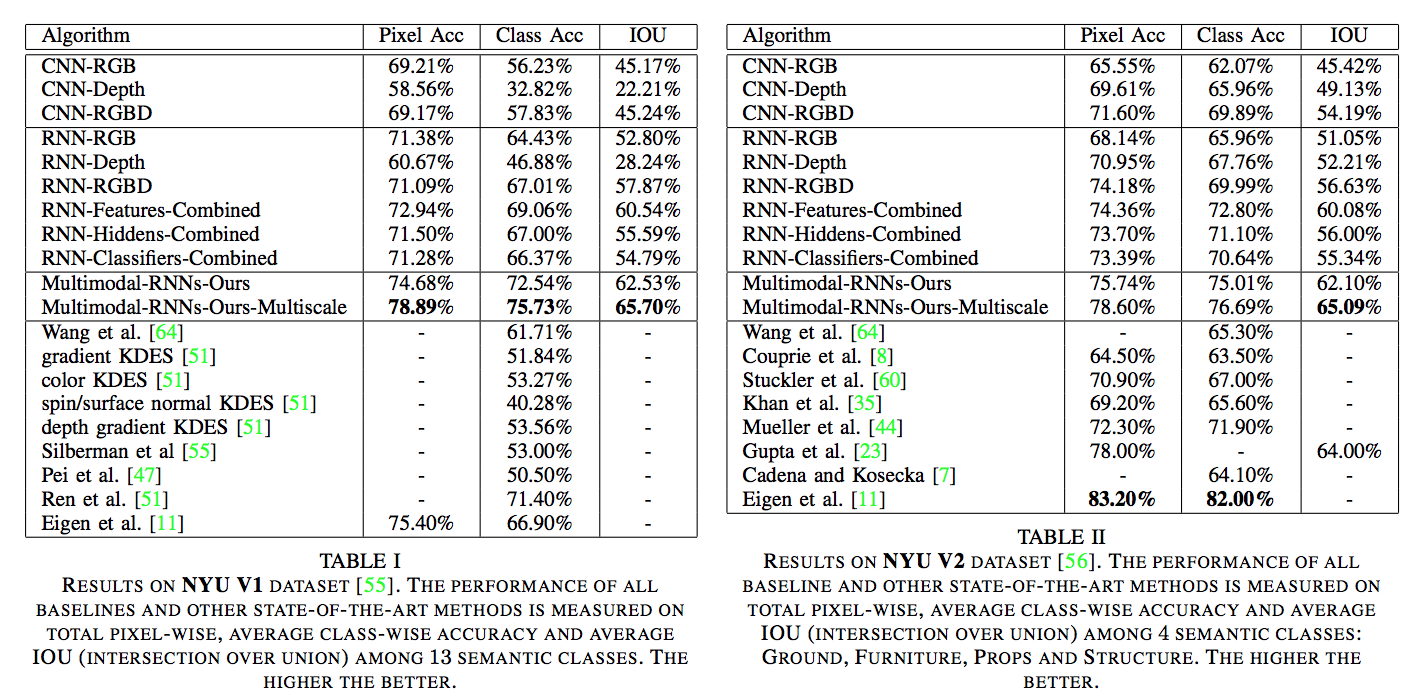
Experiments