Densely Connected Bidirectional LSTM
Code
available at https://github.com/IsaacChanghau/Dense_BiLSTM
Contributions
- Proposal of a densely-connected architecture applied to bi-directional LSTMs
- Comparison against state of the art methods for sentence classification on five datasets
Advantages
The authors point out two main advantages of their approach
- Easy trainability even of deep architectures.
- Good parameter efficiency.
Proposed model
Conceptual summary of architecture
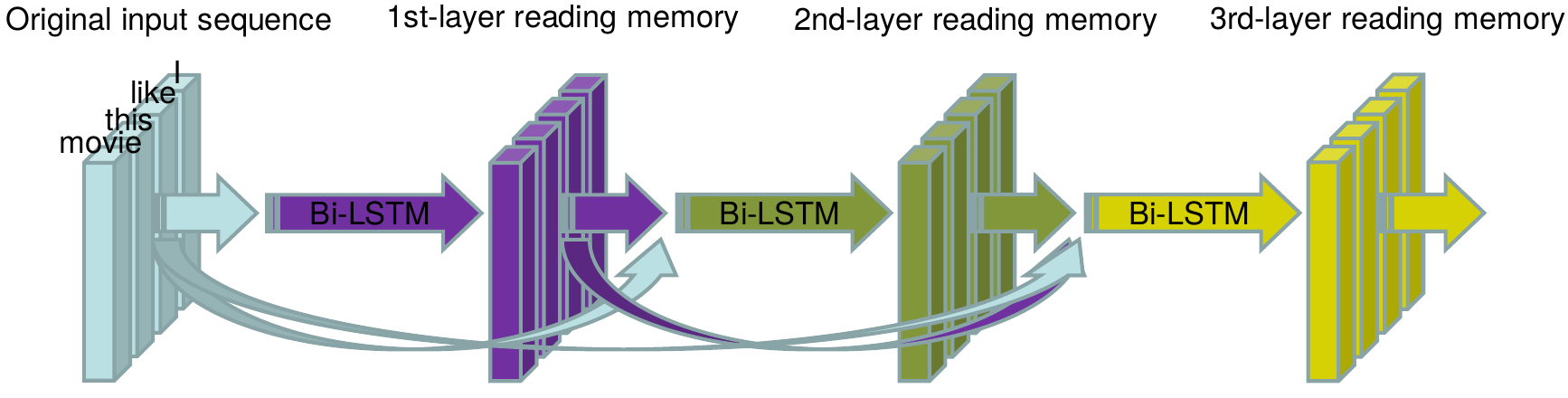
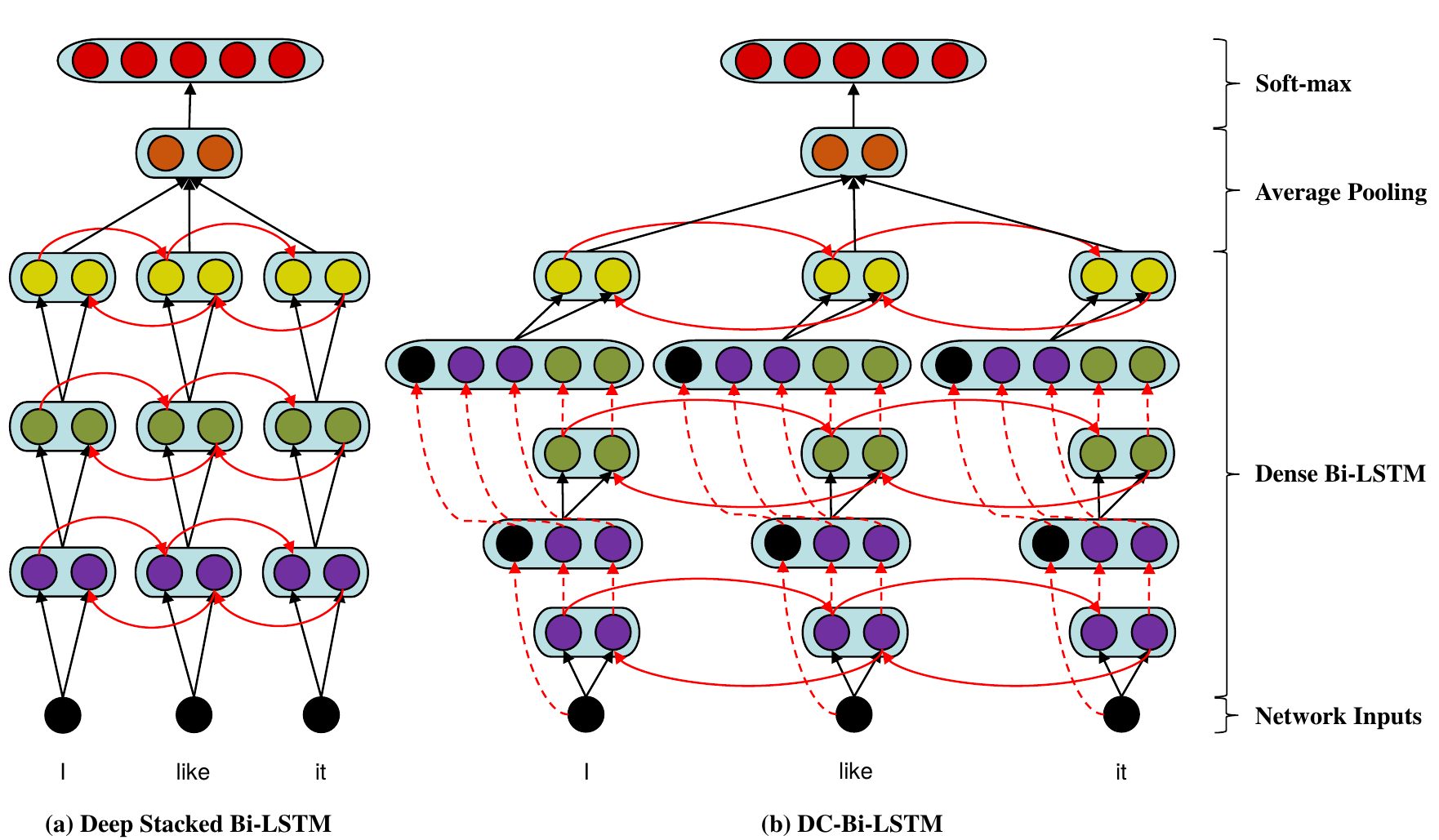
Detailed comparison with stacked RNN architecture
Experiments
Data
MR - Movie review data; positive / negative
SST-1 - extension of MR; more fine-graned labels
SST-2 - SST-1 with binary labels
Subj - sentences; subjective / objective
TREC - questions for 6 classes person, location, …
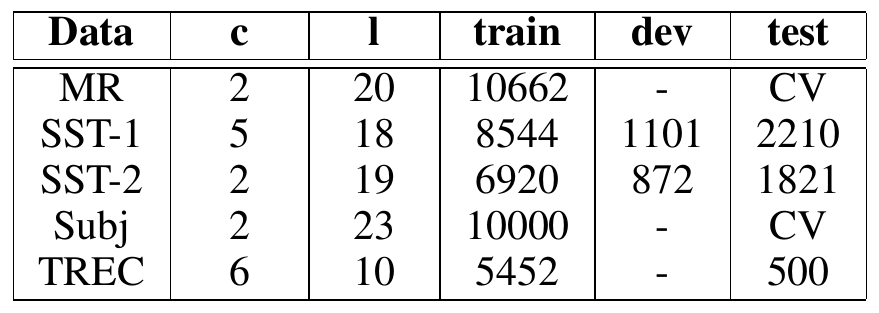
c - number of classes.
l - average sentence length.
train / dev / test - size of train / validation / test set (‘CV’ means 10-fold cross validation)
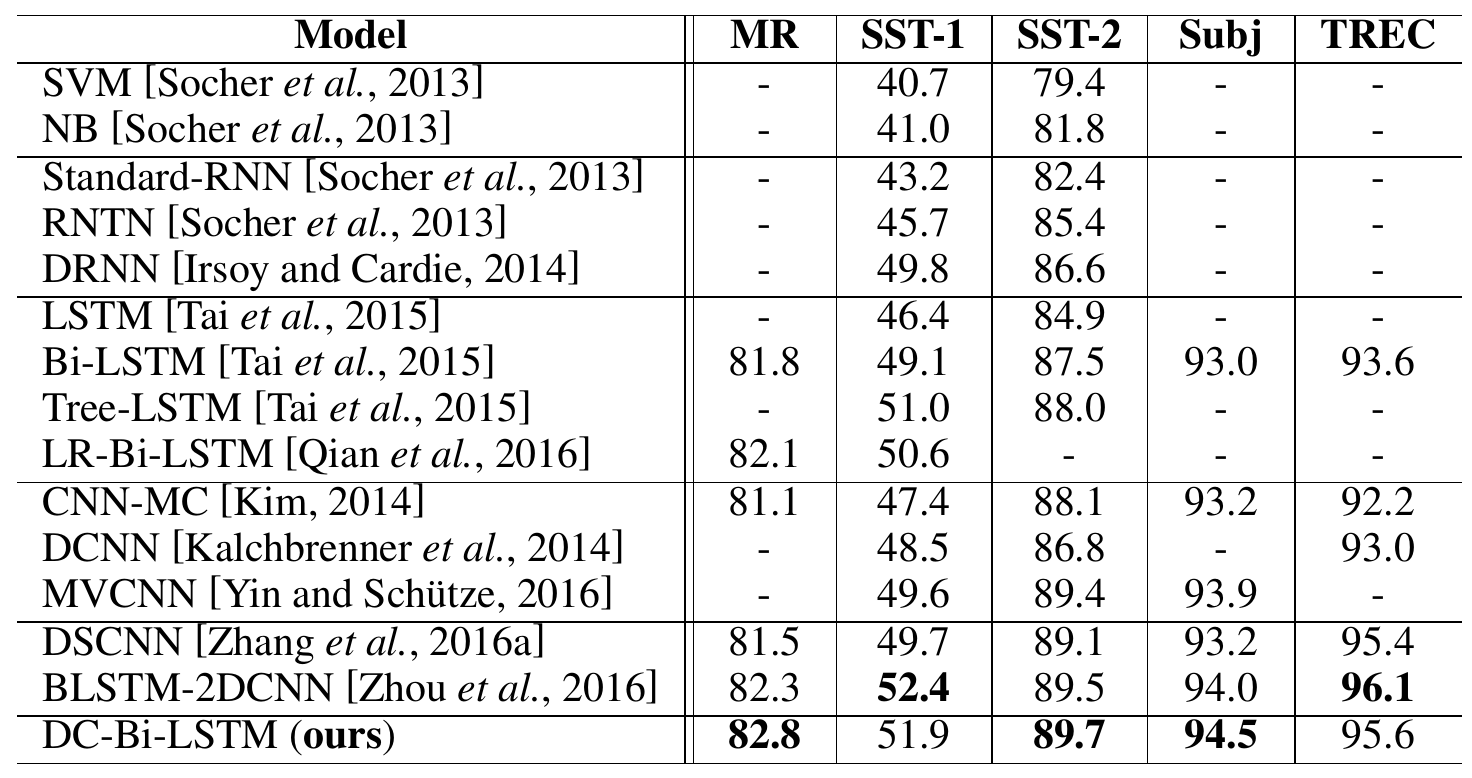
Main experiment
They achieve state-of-the-art performance superior to simple (Bi-)LSTM and CNN approaches.
Further experiments
The authors conduct further experiments varying three of their hyperparameters:
- nb_last units on last layer
- nb_layers, i.e. the stacked LSTMs
- nb_hidden units in all layers except the last
Parameter efficiency: Increasing nb_layers while keeping number of parameters constant might improve accuracy.
Increasing depth: Increasing nb_layers while keeping nb_last and nb_hidden constant improves accuracy.
Increasing width: Increasing nb_hidden while keeping nb_last and nb_hidden constant improves accuracy.
Comment - In the last two settings also the number of parameters increases. Therefore, the improved accuracy could also be explained by that. The conclusions to the effects of nb_layers and nb_hidden are not ultimately convincing.
Comments
- The authors claim that ‘the application of DenseNet to RNN’ in NLP was novel. However, in Godin (2017) the same idea was used for RNNs.