Monotonic Chunkwise Attention
Attention is widely used for offline models like Sequence-to-sequence. A huge drawback from the common soft attention algorithm is the huge time consumption, making it unusable for online tasks. This papers aims at bringing attention to real-time tasks.
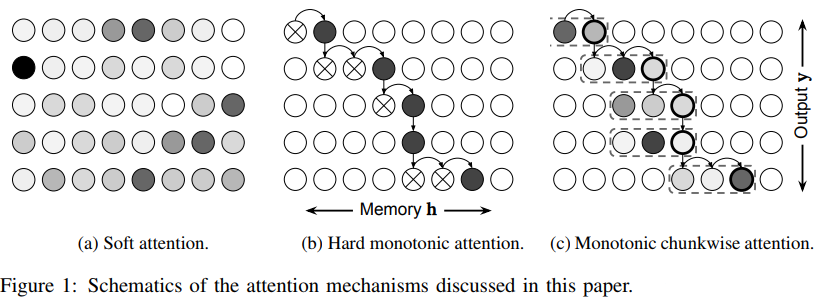
Monotonic attention
In 2017, Raffael & al. proposed a monotonic attention. At each timestep, a reader could move or attend a node along the memory axis. The feature vector would then be all of the attended nodes. This enables the use of attention for real-time applications, but the performance were not good.
Monotonic chunkwise attention
The authors propose a simple solution to improve the monotonic attention. They compute a soft attention on a chunk at each timestep. They still use monotonic attention, but the feature vector is the weighted average of the chunk instead of the value of the node to attend.
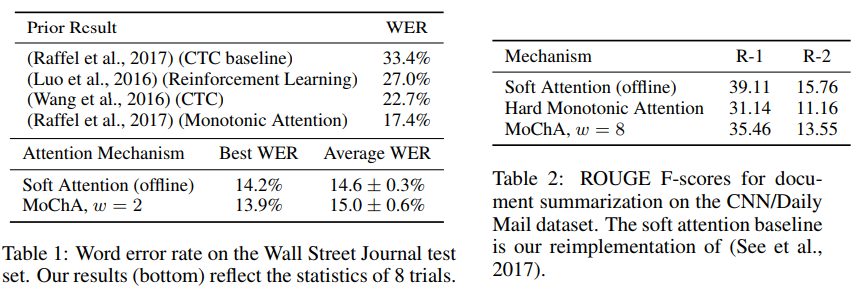
Experiments
Metrics
- Word error rate (WER), lower is better
- ROUGE-1, overlap between prediction and groundtruth for 1-gram
- ROUGE-2, overlap between prediction and groundtruth for bigram
Notes :
- Almost as good as offline methods
- Huge performance improvement compared to CTC methods
Talk
A great presentation from the author. Youtube