DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
Introduction
The segmentation method presented in this paper comes with 3 innovations:
-
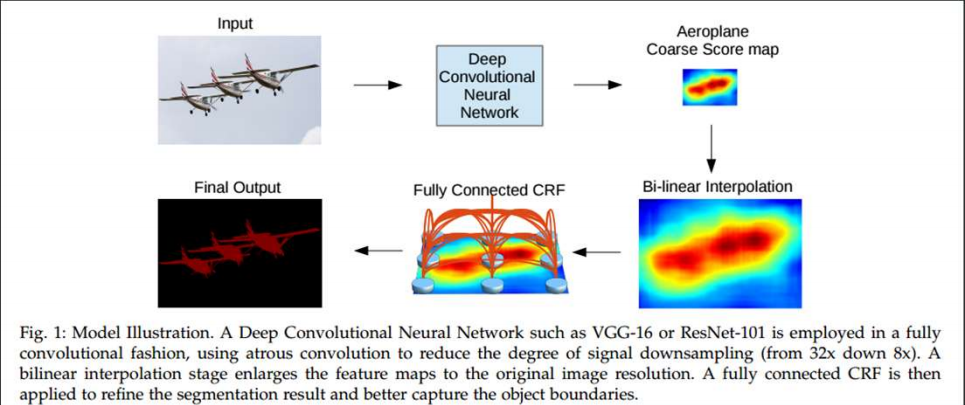
Instead of an encoder-decoder architecture, they use atrous convolutions (or dilated conv) at the end of a VGG16 and a ResNet101 to enlarge the spatial context
-
To be more resilient to multiresolution objects, they use atrous spatial pyramid pooling (ASPP)
-
They use a conditional random field (CRF) at the CNN output to improve segmentation accuracy
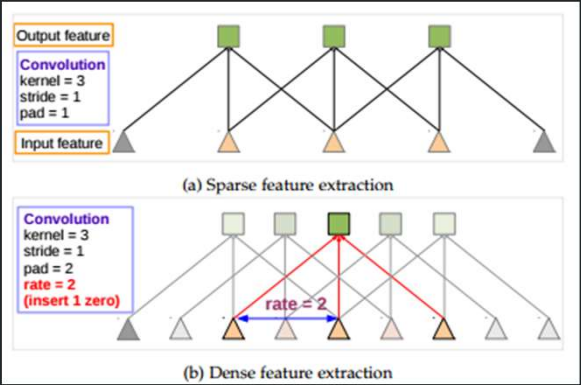
atrous conv
The atrous convolutions are convolutions with zeros in it. This increases the receptive field without increasing the number of parameters
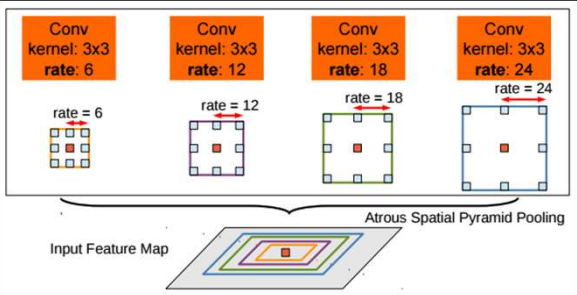
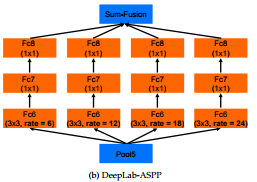
ASSP
The ASPP is a parallel architecture which aggregate the feature maps obtained with atrous conv with various rate sizes a bit like an inception model.
CRF
The CRF` minimizes the following 2 equations
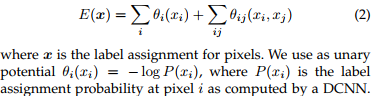
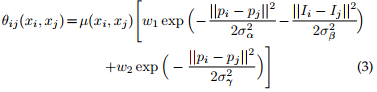
where \(p\) stands for pixel position and \(I\) for input image. This function is minimized with an iterative message passing function.
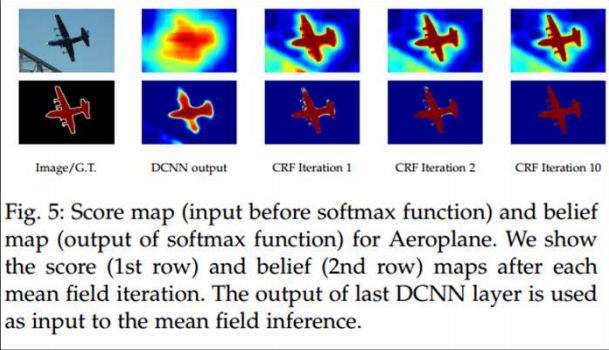
Results
 .
.
 .
.
