The Lottery Ticket Hypothesis: Training Pruned Neural Network Architectures
Context
“Recent work on neural network pruning indicates that, at training time, neural networks need to be significantly larger in size than is necessary to represent the eventual functions that they learn.”
The hypothesis
“[…] successful training depends on lucky random initialization of a smaller subcomponent of the network. Larger networks have more of these “lottery tickets,” meaning they are more likely to luck out with a subcomponent initialized in a configuration amenable to successful optimization.”
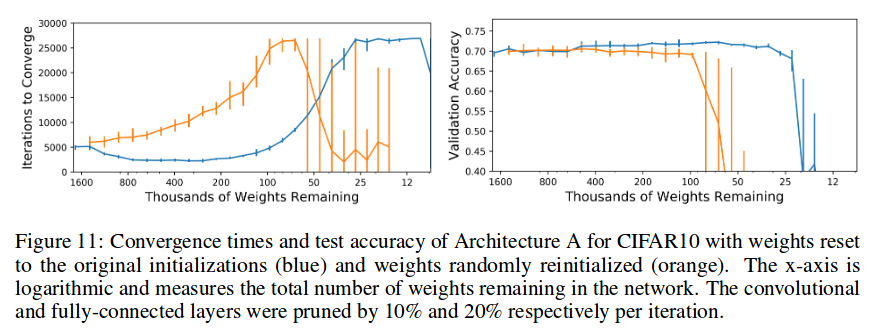
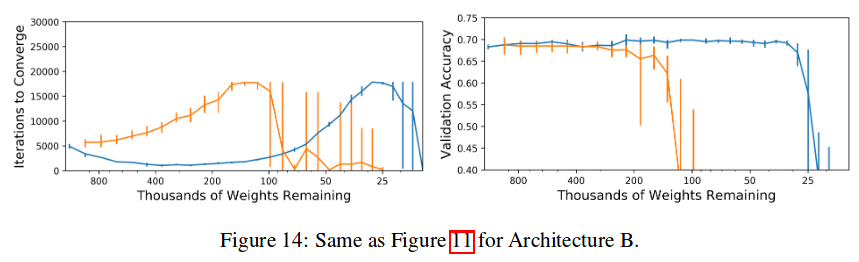
The hypothesis is empirically supported as follows:
- Train neural net; save intial state of weights
- Prune weights as much as possible without significantly reducing the accuracy (pruning criterion: prune low-magnitude weights); small network is obtained (around 90% reduction in size)
- Reinitialize the pruned network and train it to convergence; note the accuracy and convergence time
- Reinitialize the pruned network using the initial weights from step 1, and train it to convergence; note the accuracy and convergence time
- Compare aggregated results of step 4 and 5; the higher accuracy and/or convergence time of step 4 compared to step 3 supports the hypothesis.
Pics or it didn’t happen
Caveats
- No experiments on large networks (the kind of network that needs to be pruned); although the author says on reddit that he’s hard at work producing those results
- No practical takeaway (authors suggest that better initialization schemes could be discovered)