Select, Attend, and Transfer: Light, Learnable Skip Connections
They propose a light, learnable skip connections which learn to select the most discriminative channels and then attend to the most discriminative regions of the selected feature maps. The skip connections output will be a unique feature map which reduces the memory usage, the network parameters to a high extent, and improving the segmentation accuracy. They claim that the proposed skip connections can outperform the traditional heavy skip connections in terms of segmentation accuracy, memory usage, and the number of network parameters.
Segmentation Network
- 2D/3D U-net
- 2D/3D V-net
- The One Hundred Layers Tiramisu (DenseNet)
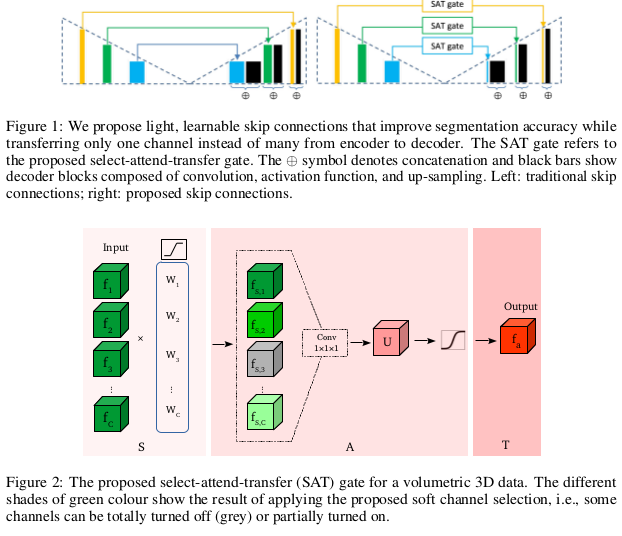
The Select-Attend-Transfer (SAT) gate
- Select: re-weighting the channels of the input, using a learned weight vector with sparsity constraints, only those channels with non-zero weights are selected.
- Attend: discovering the most salient spatial locations within the final feature map.
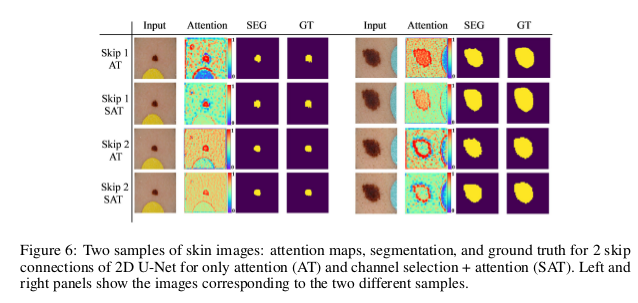
- Transfer: transferring the output into layers via a skip connection.
Experiments
- original skip connections (ORG)
- skip connections, transfer only an attention map (AT)
- skip connections, transfer several soft selected channels (ST)
- skip connections, transfer only one attention map produced from soft selected channels (SAT)
N is the total number of channels C before skip connection
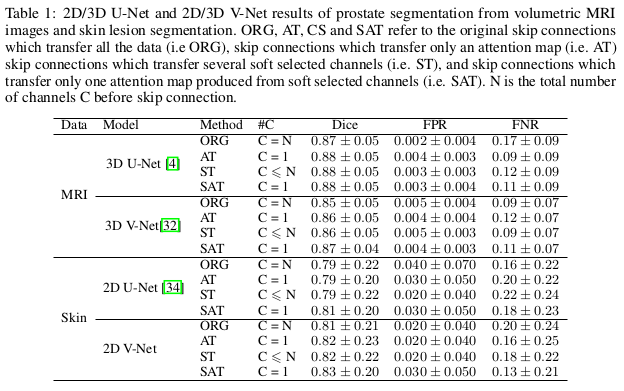
On the Tiramisu, they reach an improvement of 2% of Dice score for MRI and 3% for the Skin, compare to the original skip connections.
For the parameters, it’s between 7% and 30% of parameters reduction depending on the network.
Improvement
- channels selection and attention: fewer feature maps, less memory use, focus on spatial regions in the input.
- consistent segmentation: segmentation more consistent, smaller std than the original skip connections.
- SAT in Densely connected network: help preventing gradient vanishing, reduce memory usage in blocks.