Knowledg Distillation on Object Detection
Description
They proposed an end-to-end trainable framework for learning multi-class object detection through knowledge distillation. A teacher network (a pretrained network with more parameters and deeper) supervises and leads to better student performance which the knowledge is received from teacher is more informative.
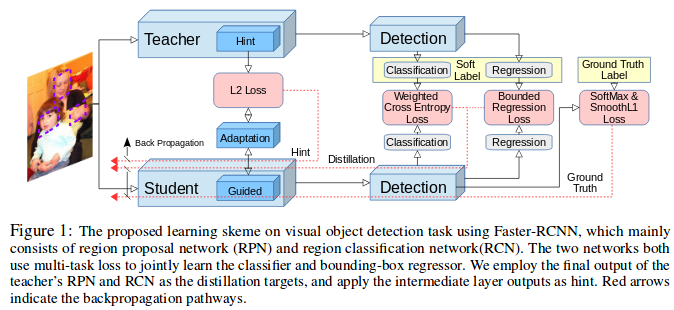
Faster-RCNN is their object detection framework which is composed of two modules:1) a region proposal network(RPN) that generates object proposals, and 2) RPN inputs to a classification and regression network(RCN) that return the detection score and bounding boxes.They learn a student object detector by using Knowledge of a high capacity teacher detection network.There is three steps:
1) Encourage the feature representation of a student network is similar to that of the teacher network. 2) The soft teacher targets in classification and regrestion is applied to transfer knowledge to student. 3) The student have a more loss by groundtruth and its prediction.
Losses:
The soft labels contain information about the relationship between different classes as discovered by teacher. By learning from soft labels, the student network inherits such hidden information. In object detection, the possible errors are misclassifications between background and foreground, they address this with a class-weighted cross entropy.
For classification, they aplied cross entropy losses in hard target(student prediction and groundtruth) and a class-weighted cross entropy for soft target( prediction between student and teacher)
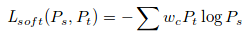
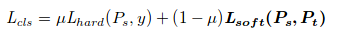
For regression, because the real value regression outputs are unbounded, the teacher may provided a direction that is contrary to groundtruth.The authors, instead of using teacher’s regression output as a target, they inforce The student’s regression to be as close to the ground truth label, but once the quality of the student surpasses that of the teacher with a certain margin, they do not provide additional loss for the student.
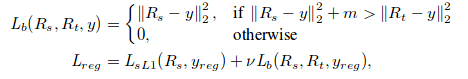
For similarity between features in intermediate layer in student(V) and teacher(Z) network, they apply L2 distance:
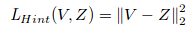
Finally the loss is :
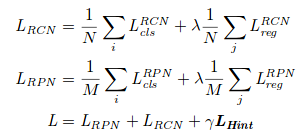
where N and M are the batch-size for RCN and RPN, respectively and \lambda and \gamma are hyper-parameter.
Experiments
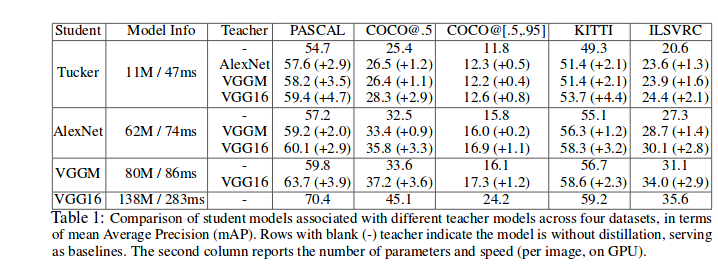
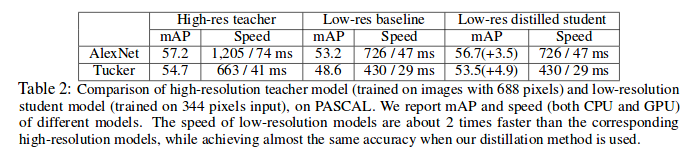
They applied two different settings. First, applying different networks size in student and teacher and second, with keeping the same model for both, smaller input image size for the student model and larger input image size for the teacher is applied.