SqueezeNet: AlexNet-Level Accuracy with 50X Fewer Parameters and <0.5MB Model Size
SqueezeNet achieves AlexNet-level accuracy on ImageNet with 50x fewer parameters. Additionally, with model compression techniques, authors are able to compress SqueezeNet to less than 0.5MB (510× smaller than AlexNet).
The main ideas of SqueezeNet are:
-
Using 1x1(point-wise) filters to replace 3x3 filters, as the former only 1/9 of computation.
-
Using a bottleneck layer to reduce depth to reduce computation of the following 3x3 filters.
-
Downsample late to keep a big feature map.
The building brick of SqueezeNet is called fire module, which contains two layers: a squeeze layer and an expand layer.
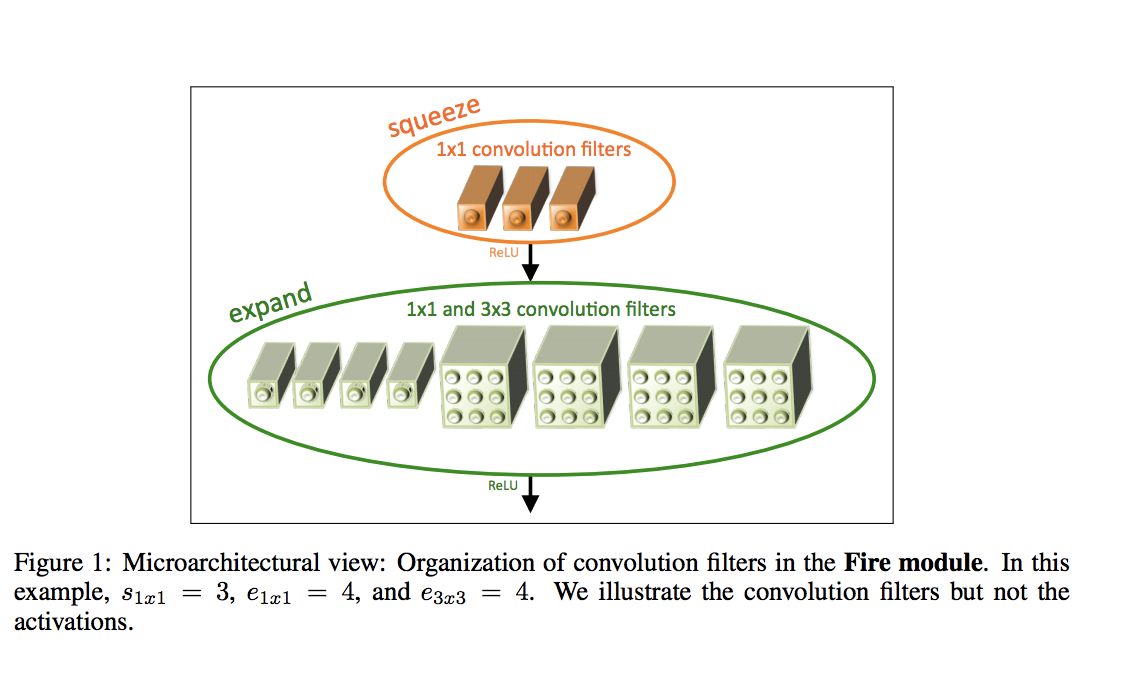
A SqueezeNet stackes a bunch of fire modules and a few pooling layers. The squeeze layer and expand layer keep the same feature map size, while the former reduce the depth to a smaller number, the later increase it. Another common pattern is increasing depth while reducing feature map size to get high level of abstraction.
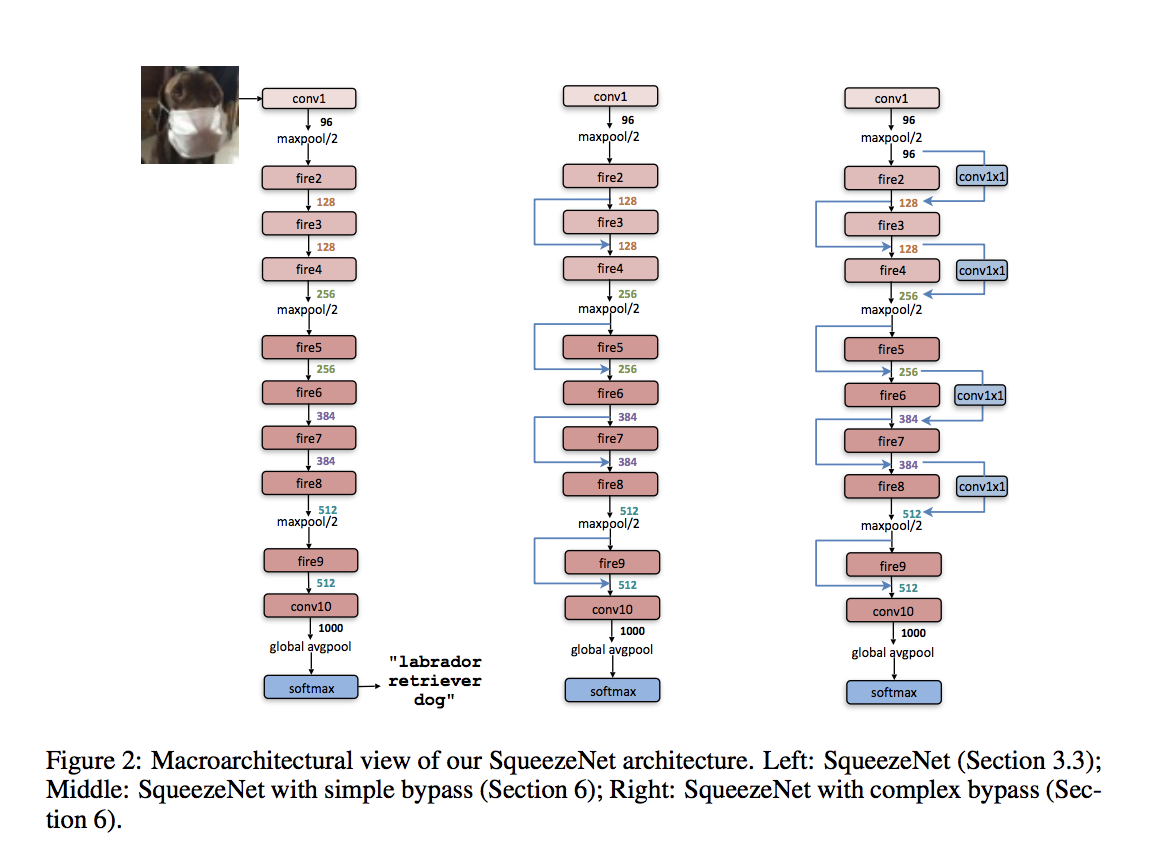
Results
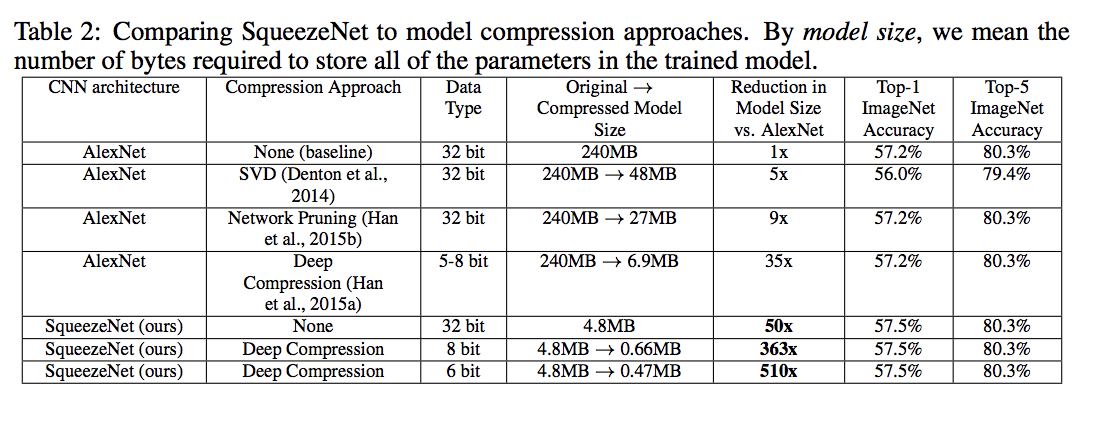
Code
Code from the authors and for various architectures can be found here