IM2HEIGHT: Height Estimation from Single Monocular Imagery via Fully Residual Convolutional-Deconvolutional Network
Description
The goal of that paper is to estimate building height from a single monocular1 remote-sensing image. The authors propose a fully convolutional-deconvolutional network architecture being trained end-to-end, encompassing residual learning. This approach is decomposed into two parts, convolutional sub-network, and deconvolutional sub-network.
The former corresponds to feature extractor that transforms the input remote sensing image into high-level multidimensional feature representation, whereas the latter plays the role of a height generator that produces height map from the feature extracted from the convolutional sub-network.
Normally, LiDAR is used to do the DSM, but for satellite images, the resolutions are very bad and the height estimation from monocular vision poses a problem, as one captured remote sensing image may correspond an infinite number of possible real-world scenarios. This is why deep-learning can help, by training a model on knowing the DSM you may be able to predict a good estimation from a place with no DSM values.
Summary
- Input: RGB images.
- Ground Truth: DSM.
- Proposal: end-to-end deep residual network (base on the Eigen-Net performance2).
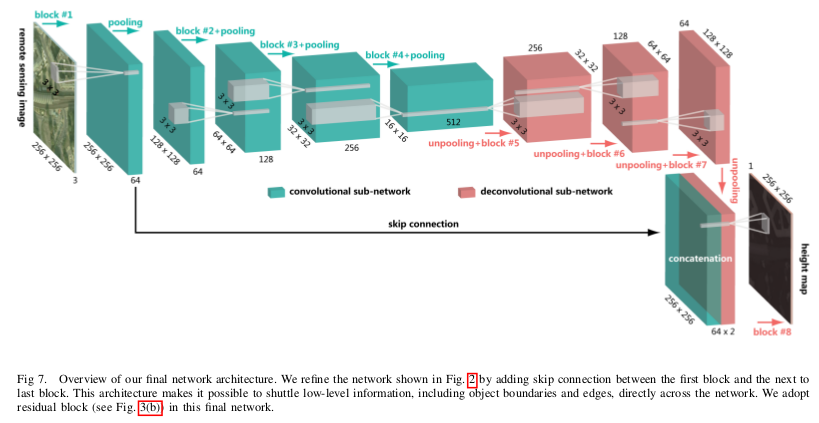
Experiments
Dataset: Potsdam (only one dataset available with those specifications).
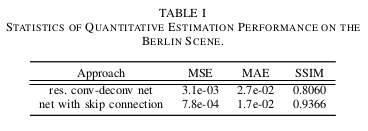
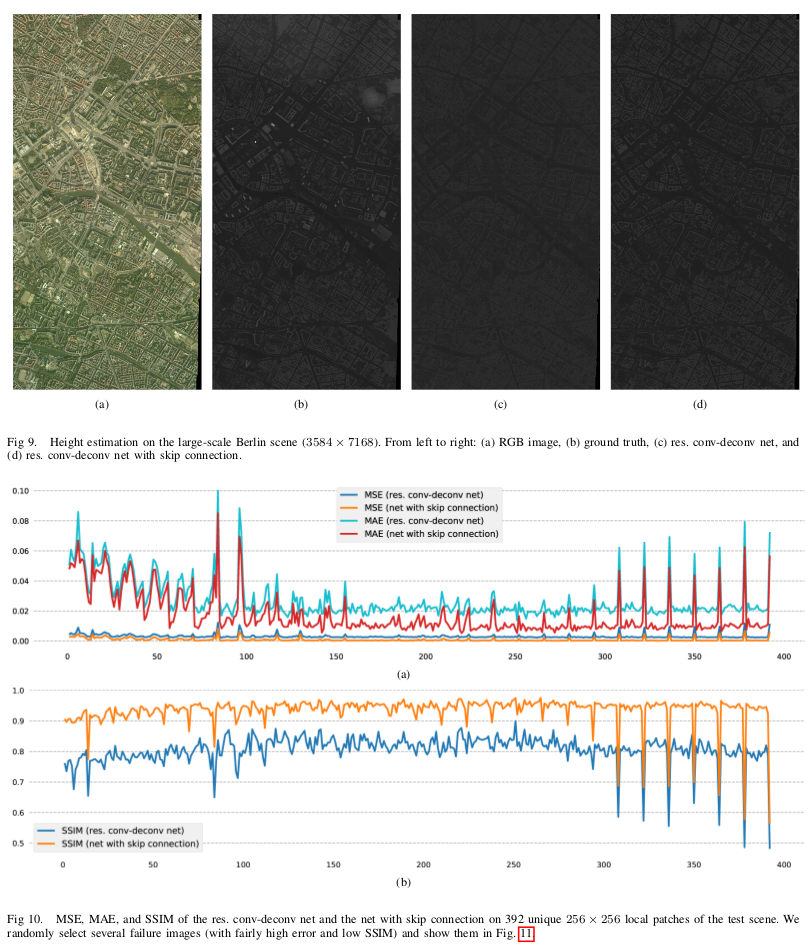

-
Monocular mean just one sensor, normally to do a DSM (demographic surface model) 2 sensor is used or a LiDAR(plane or bad resolution for satellite - 5m). ↩
-
D. Eigen, C. Puhrsch, and R. Fergus, “Depth map prediction from a single image using a multi-scale deep network,” in Advances in Neural Information Processing Systems (NIPS), 2014. ↩