Learning Aerial Image Segmentation from Online Maps
What they do
- Pixel-accurate, but small-scale ground truth available.
- Less accurate reference data that is readily available in arbitrary quantities, at no cost.
Tools
- OpenStreetMap (OSM)

Description
They use OSM like weakly labeled training data for three classes, buildings, roads and background with RGB orthophotos from Google Maps.
The author’s hypotheses
- The volume of training data can possibly compensate for lower accuracy of the labeling.
- The large variety present in very large training set could potentially improve the classifier’s ability to generalize to new unseen location.
- The addition of the large volume of weak data to low volume high-quality data could potentially improve the classification.
- If low-accuracy, large-scale training data helps, it may allow substituting a large portion of the manually annotated high-quality data.
Model
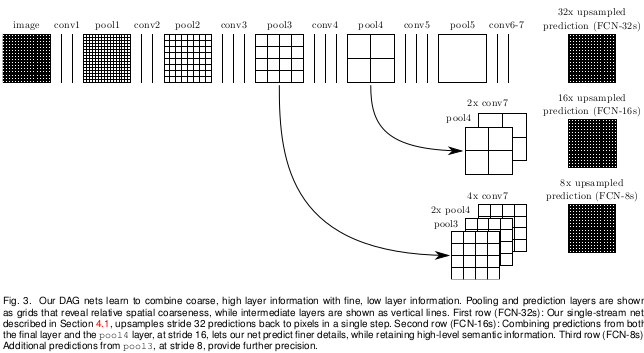
FCN (Fully convolutional network) with modifications and as input, an 500x500pixel patch (mini batch 1 image).
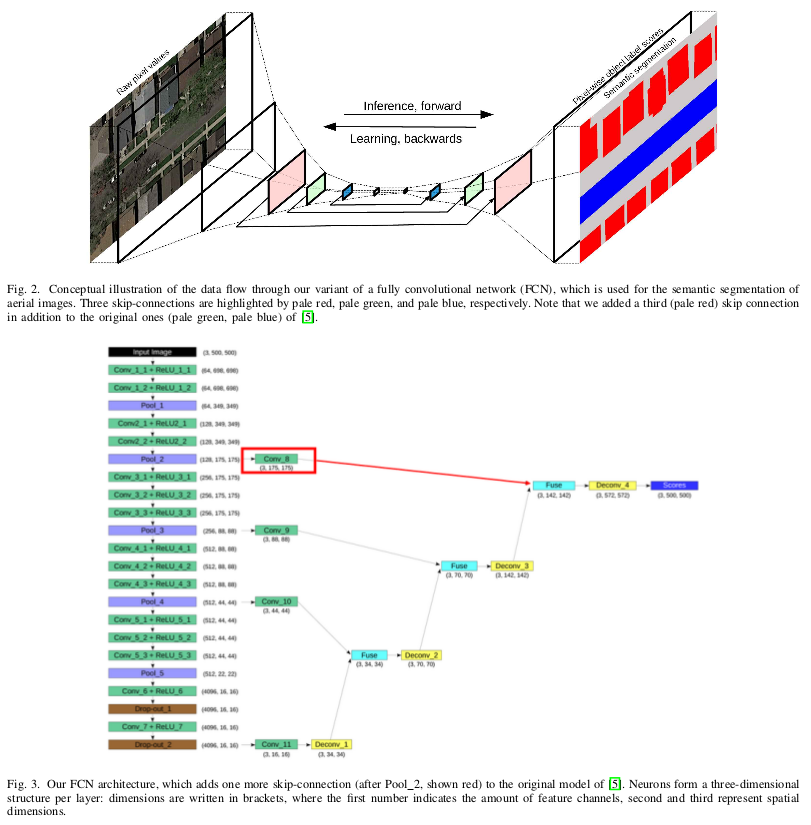
They make some pre-training before the real training to get better results. One by the Pascal VOC 20101 and the other with the OSM data.
Experiments
- Complete substitution (No manual labeling).
- Augmentation (pre-training help or not).
- Partial substitution (pre-training with OSM labeling in the training).
Datasets
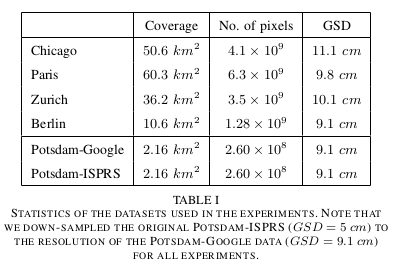
ground sampling distance (GSD).
Potsdam - 1 image (6000x6000 pixel) = 144 images (500x500 pixel), only 21 have been manually labeled.
Results
For Chicago with only the OSM training.

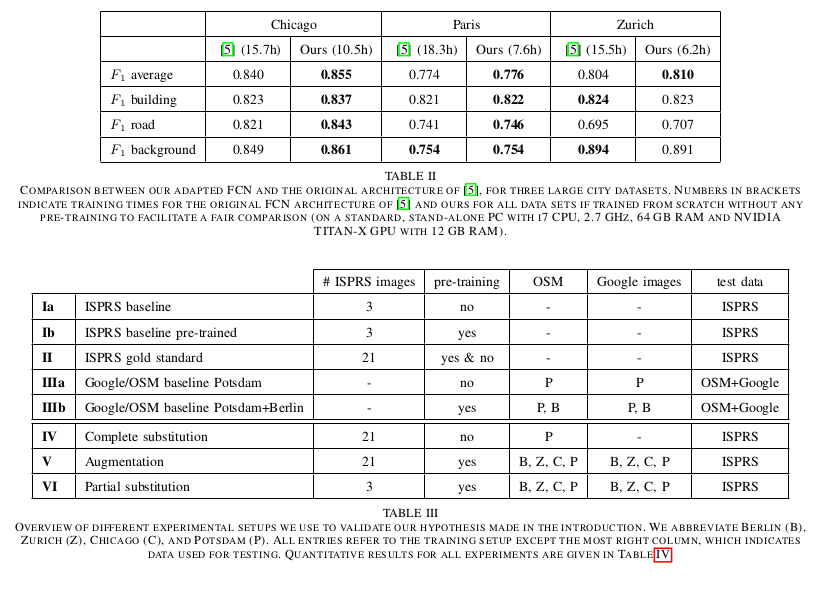
The methode 52 is:
The finals results are:
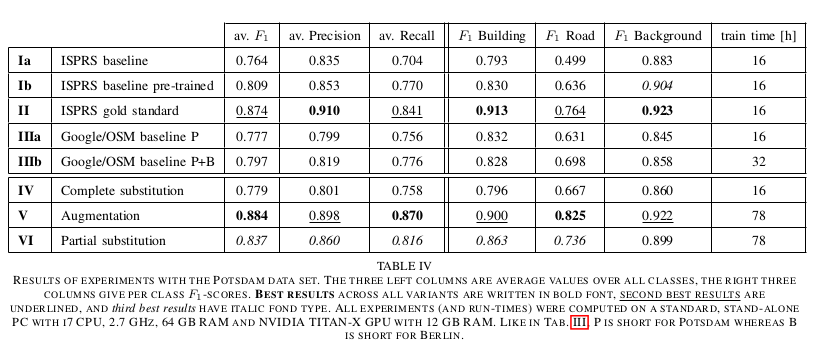

Conclusions
- Large scale, nevertheless significantly improves segmentation performance, and improves generalization ability of the models.
- Training only on open data, without manual labelling, achieves reasonable results.
- Large-scale pre-training with OSM labels significantly benefits semantic segmentation.
-
M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman, “The Pascal visual object classes (VOC) challenge,” International Journal of Computer Vision, vol. 88, no. 2, pp. 303–338, 2010. ↩
-
J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in CVPR, 2015. ↩