Aggregated Residual Transformations for Deep Neural Networks
Paper:
The main contribution of this paper is a new “cardinality” for the resnet block.
Model
The difference between the resnet block and resnext block is really simple and well summarized in Figure 1.
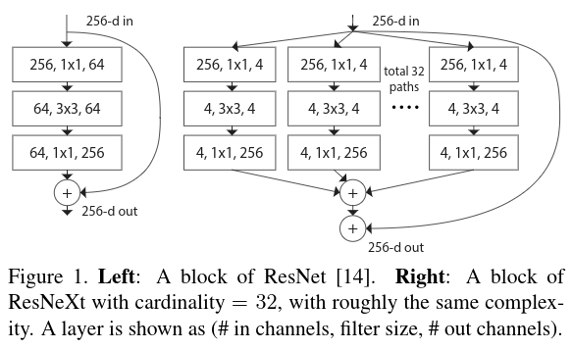
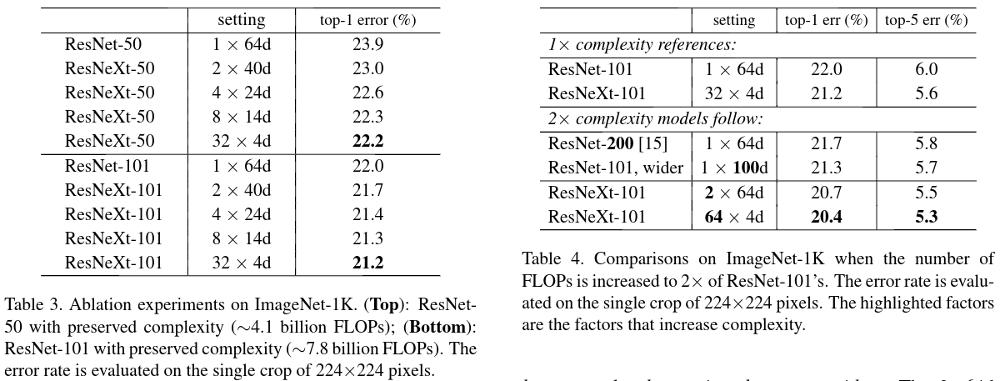
They split the convolution in multiple parts (Figure 1 in 32 parts). They argue that the cardinality dimension controls the number of complex transformations and is more effective than width or depth dimension. Table 1 show side by side a resnet with a resnext with the same number of parameters and the same number of FLOPS.
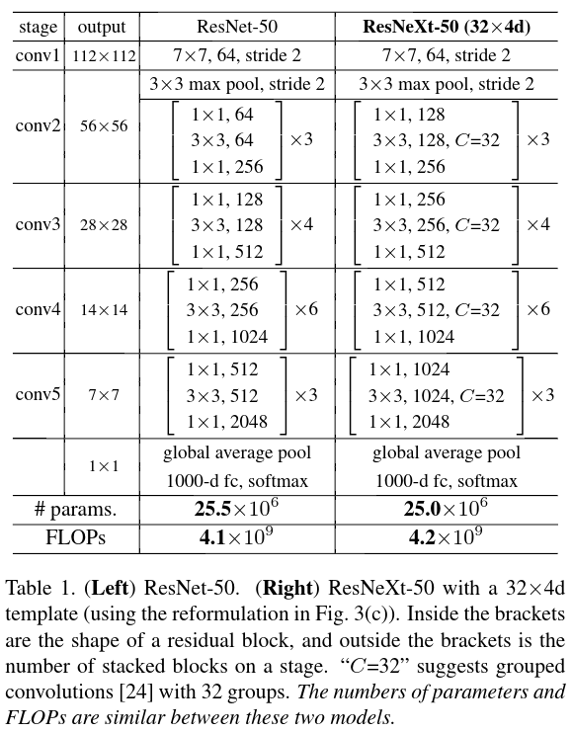
where \(C\) is the cardinality discussed before and it produces groups of convolutions as in Figure 1.
Results
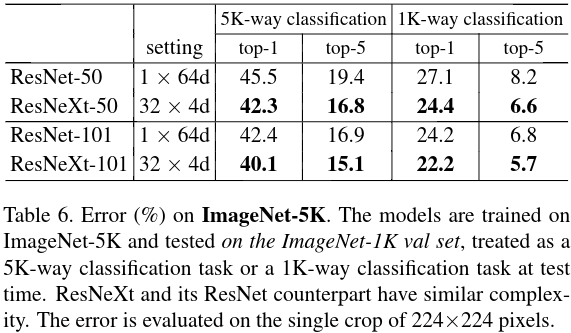
They report results on three and a half dataset Imagenet 1k, Cifar10, MSCOCO, and Imagenet 1k trained on Imagenet 5k
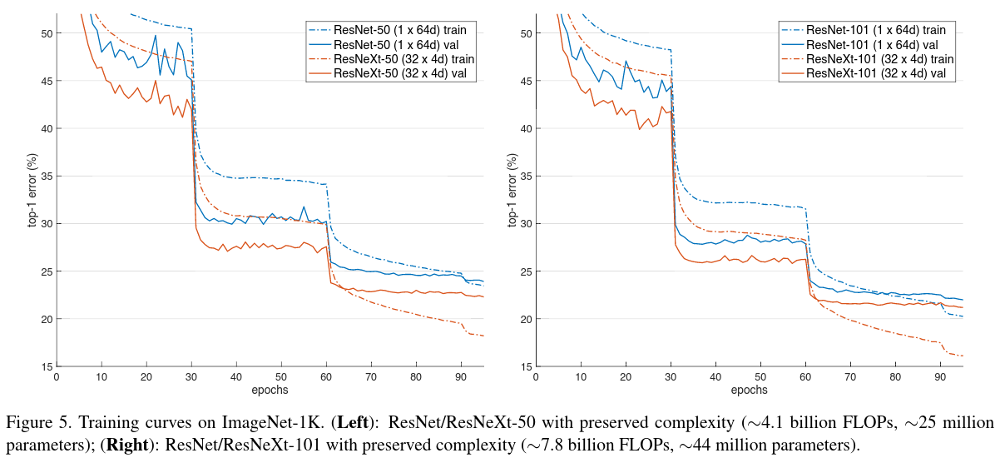
Imagenet 1k
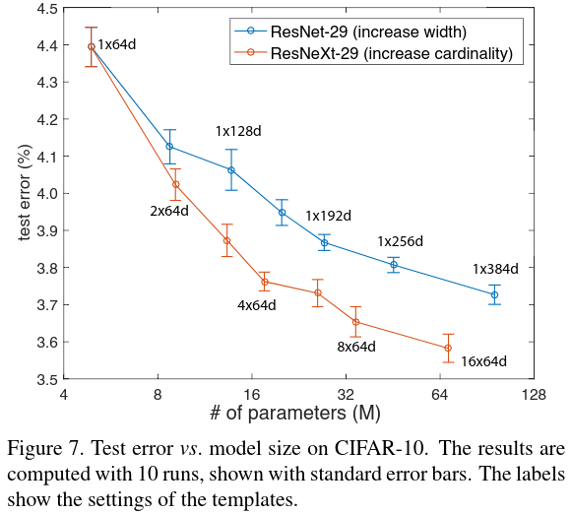
Cifar10
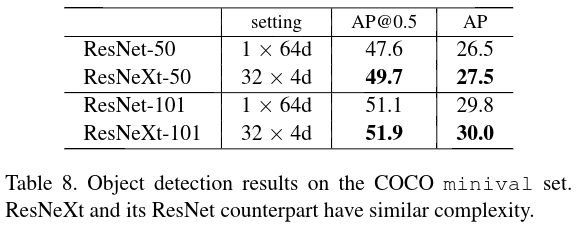
MSCOCO