Learning from Simulated and Unsupervised Images through Adversarial Training
Summary
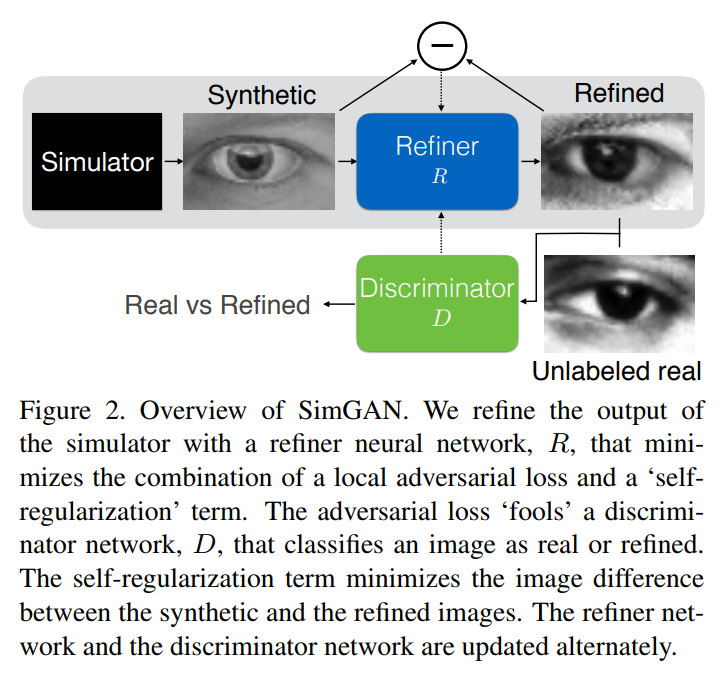
The refiner \(R_{\theta}\) is a fully convolutional network without striding or pooling.
In addition to the usual adversarial loss (\(l_{real}\)), a regularization loss is used to preserve “annotation” information from the simulator (\(l_{reg}\)).

The function \(\psi\) in the regularization term is a mapping to feature space. It is usually the identity function, but in some cases the authors use other features, like the mean of color channels or a convnet output for example.
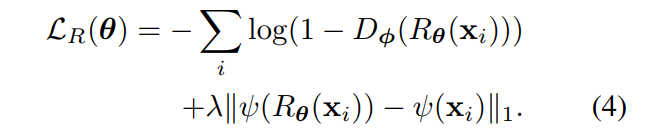
Generated images history for discriminator training
The training set for the discriminator update is built using 50% real images, 25% of refined images generated by the latest generator, and 25% of refined images generated by past versions of the generator. This is done to improve the stability of adversarial training. The authors note that this method is complimentary to using a running average of the model parameters.
Experiments and Results
Datasets:
- Appearance-based gaze estimation on MPIIGaze dataset
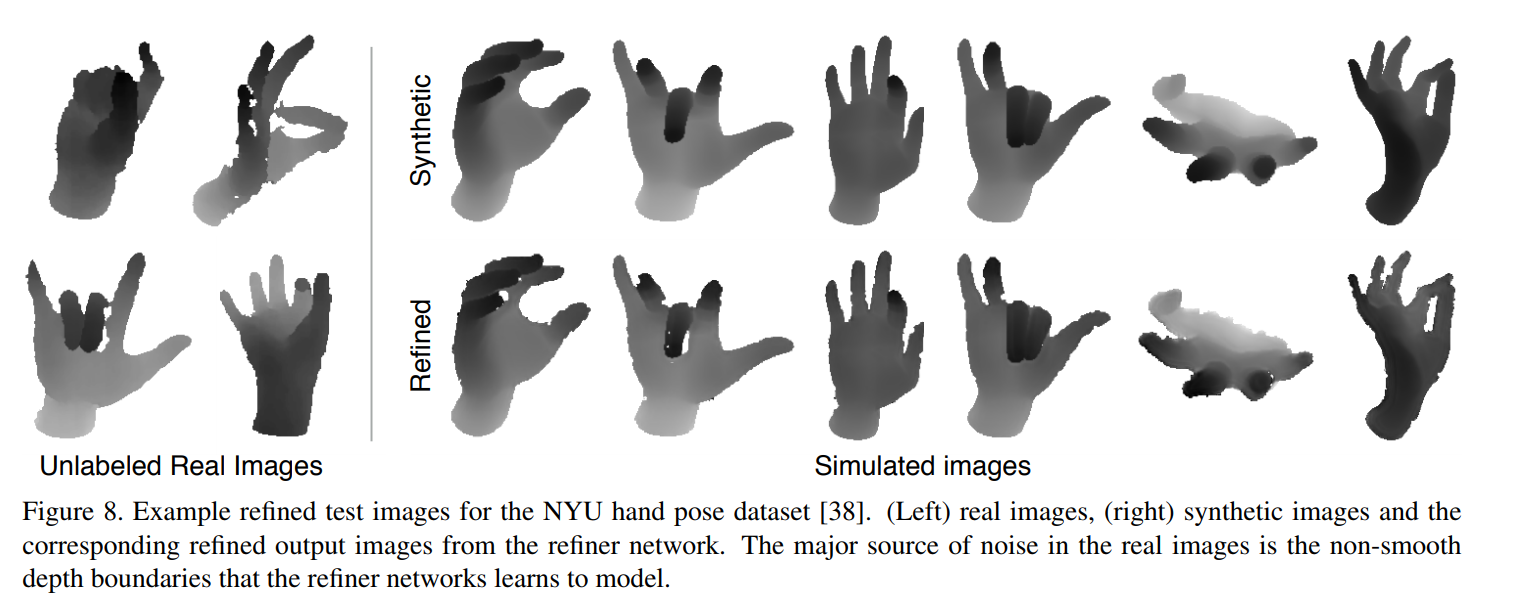
- Hand pose estimation on NYU hand pose dataset of depth images

Visual Turing test A “Visual Turing test” for classifying real vs. refined images was done, and the human accuracy was 51.7%, showing that refined images are almost indistinguishable from real images.
Training on refined synthetic data outperforms training on purely synthetic data by 22.3%.
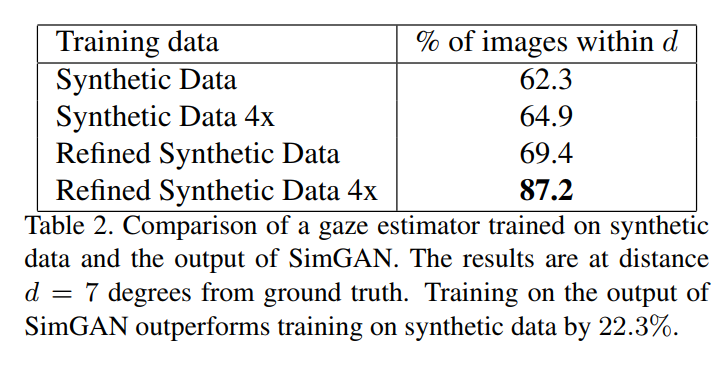
Comparison to other methods