DESIRE: Distant Future Prediction in Dynamic Scenes with Interacting Agents
Summary
The authors propose a model called DESIRE whose goal is to predict future locations of objects in multiple scenes. The system takes into account the past motion history as well as the scene context to account for interactions among the agents.
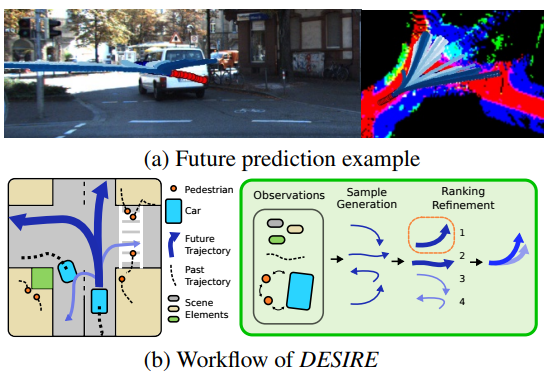
As mentioned by the authors (X are the past locations of each object, I is the image at time t, and Y is the future locations of each object),
Learning a deterministic function f that directly maps {X, I} to Y will under-represent potential prediction space and easily over-fit to training data. Moreover, a naively trained network with a simple loss will produce predictions that average out all possible outcomes.
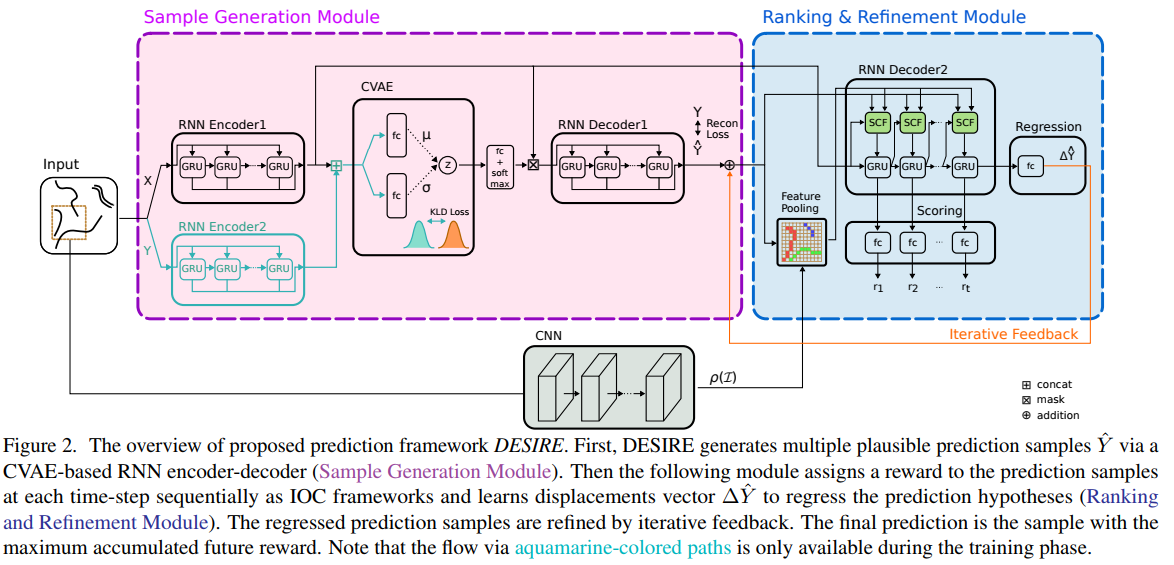
As a solution, they propose a complex model that first obtains a diverse set of hypothetical future prediction samples employing a conditional variational autoencoder, which are ranked and refined by the following RNN scoring-regression module. One important element of their model is the use of a Conditional Variational Autoencoder to encode the input paths into a latent variable space.
Experiments and Results
It works! at least on the kitti dataset.
