Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
Summary
The authors propose a super-resolution GAN (SRGAN) using a ResNet and a novel “perceptual” loss function.
The perceptual loss is defined using high-level feature maps of a VGG network fed to the discriminator.
The SRGAN is the new state of the art by a large margin for super-resolution with high upscaling factors (4x)

Perceptual loss
The perceptual loss is a combination of a content loss and an adversarial loss.
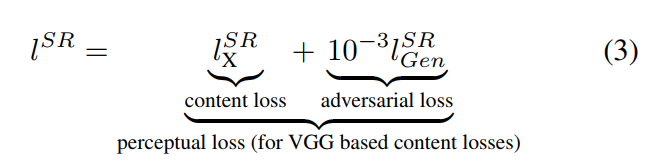
Content loss
Instead of using a pixel-wise MSE as a content loss, the authors define a new VGG loss based on the activations of 19 pre-trained VGG layers.
The VGG loss is the L2 distance between the features of a reconstructed image and the reference image.
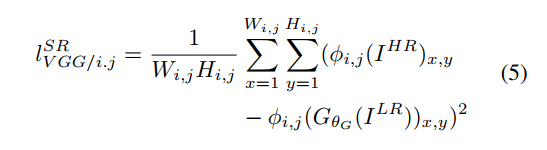
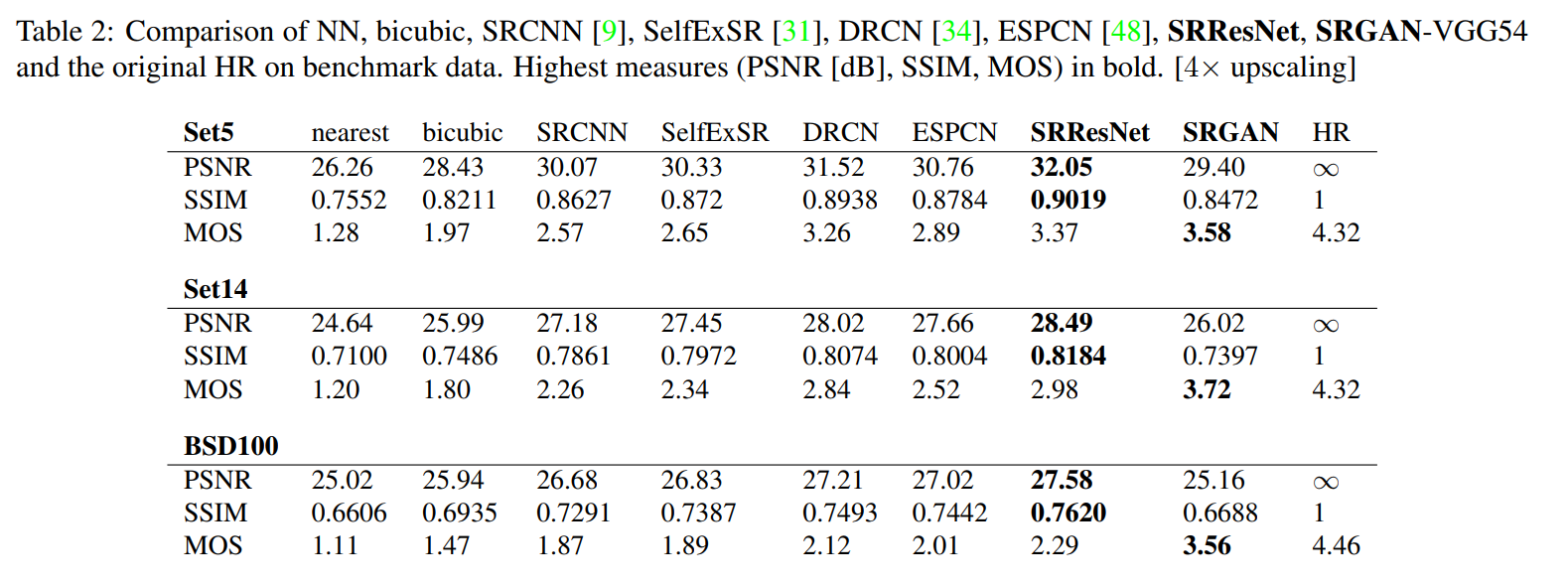
Experiments and Results
Datasets:
- Set5
- Set14
- BSD100
A scale factor of 4x is used (i.e. 16x reduction in pixels).
Networks are trained on 350K random images from ImageNet.
Low resolution images are obtained using a bicubic kernel for downsampling.
MOS testing
A Mean Opinion Score is used to compare methods. 26 raters assigned a score from 1 (bad quality) to 5 (excellent quality) to the super-resolved images. For each image, multiple versions from different methods were rated, for a total of 1128 instances per rater, presented randomly.
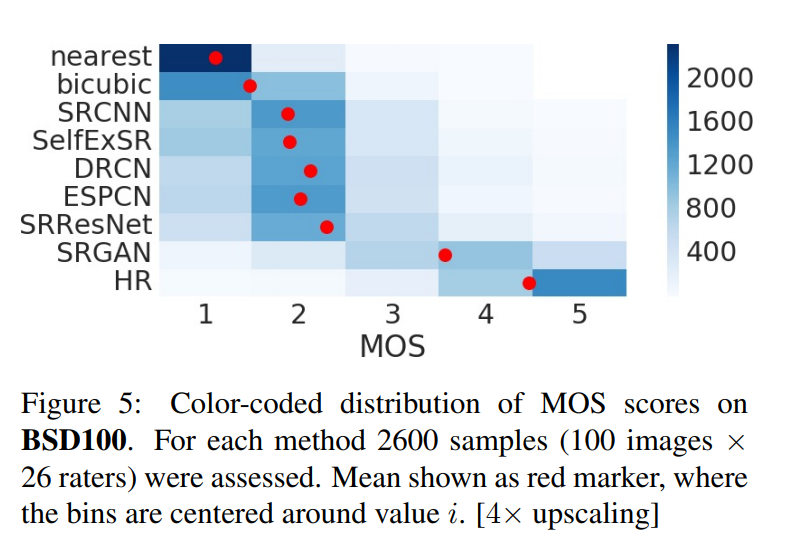

Results show that while the SRGAN does not achieve better results than ResNet in terms of PSNR or SSIM, it is consistently better when evaluated by a human.