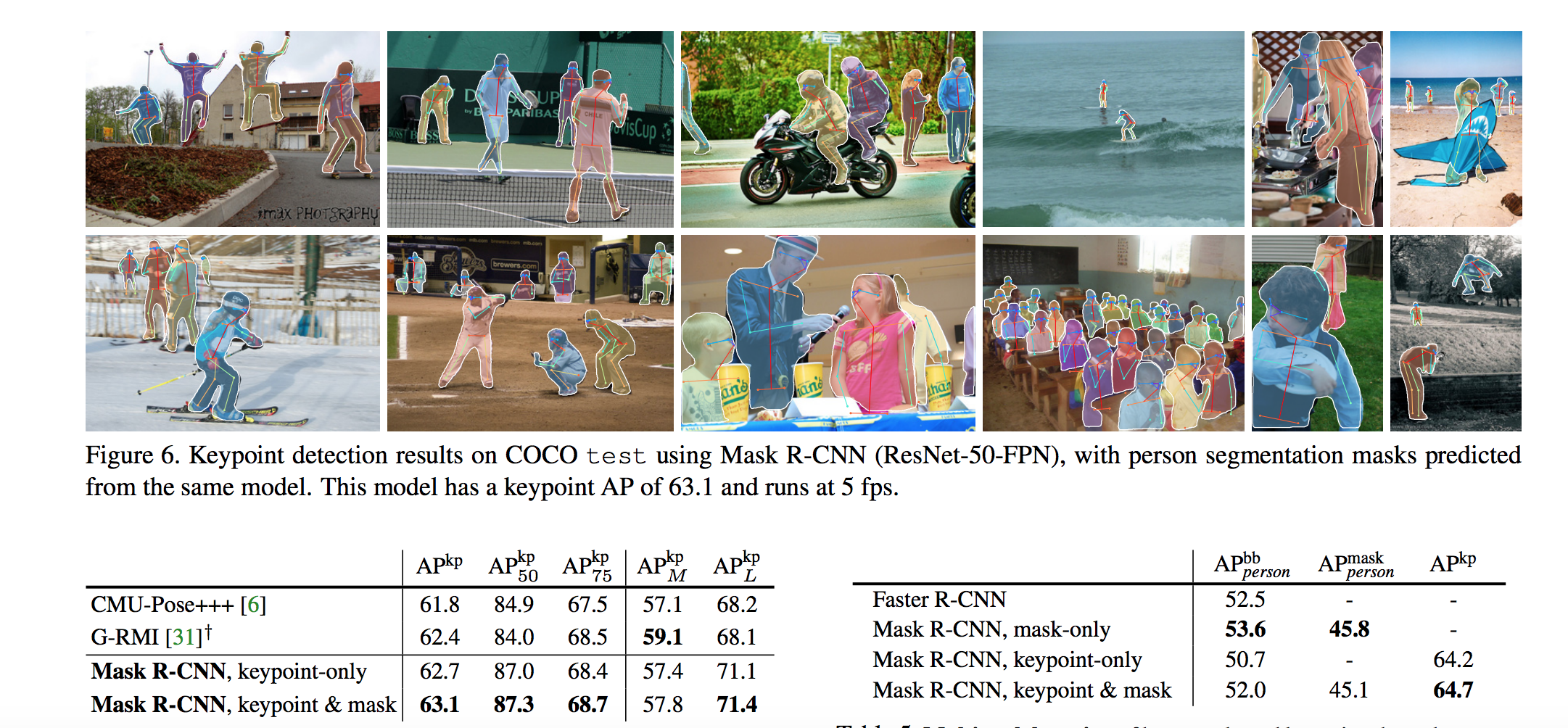
Mask R-CNN
R-CNN and Fast R-CNN
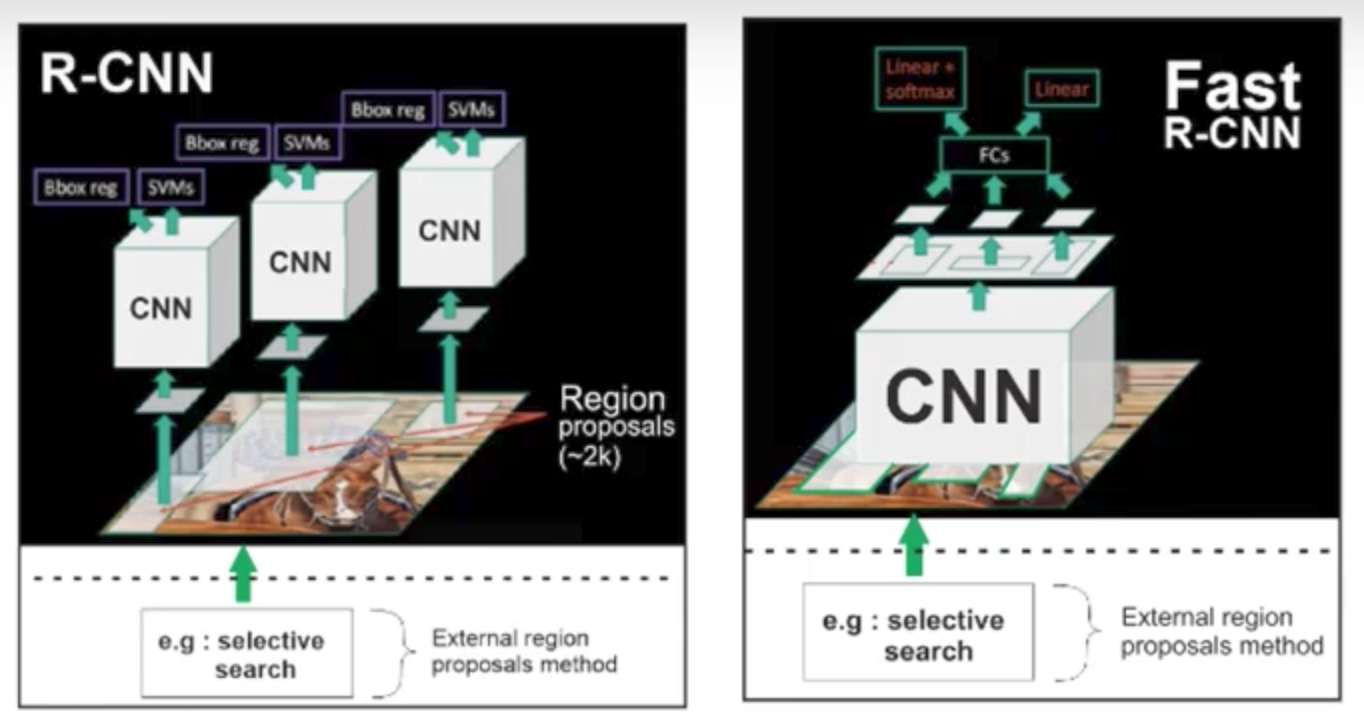
R-CNN is the grand-daddy of Faster R-CNN. It’s first proposed regions, then extracted features, and then classified those regions based on their features.It requires a forward pass of the CNN for every single region proposal for every single image and It has to train three different models separately - the CNN to generate image features, the classifier that predicts the class, and the regression model to tighten the bounding boxes.
Why not run the CNN just once per image and then find a way to share that computation across the all proposals?
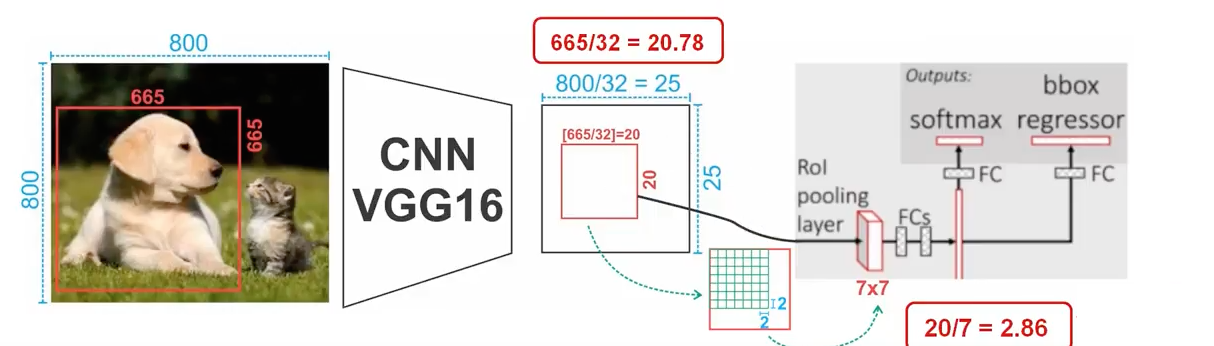
Fast R-CNN The Fast RCNN method receive region proposals from some external system (Selective search). This proposals will sent to a layer (Roi Pooling) that will resize all regions with their data to a fixed size. This step is needed because the fully connected layer expect that all the vectors will have same size
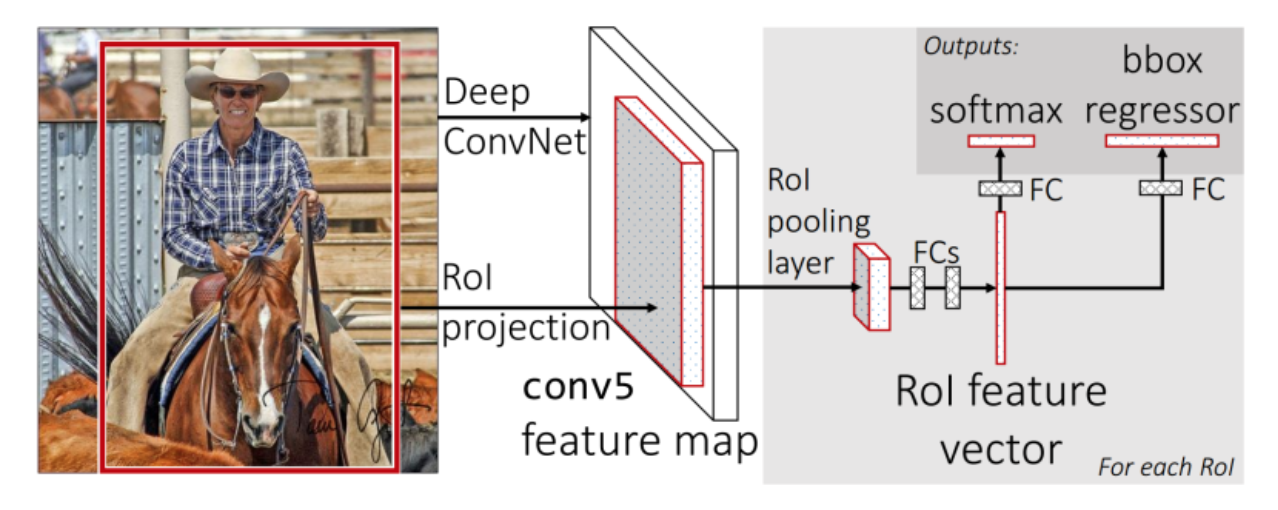
RoI (Region of Interest) Pooling
It’s a type of max-pooling with a pool size dependent on the input, so that the output always has the same size. This is done because fully connected layer always expected the same input size.
Faster R-CNN
So why not reuse those same CNN results for region proposals instead of running a separate selective search algorithm?
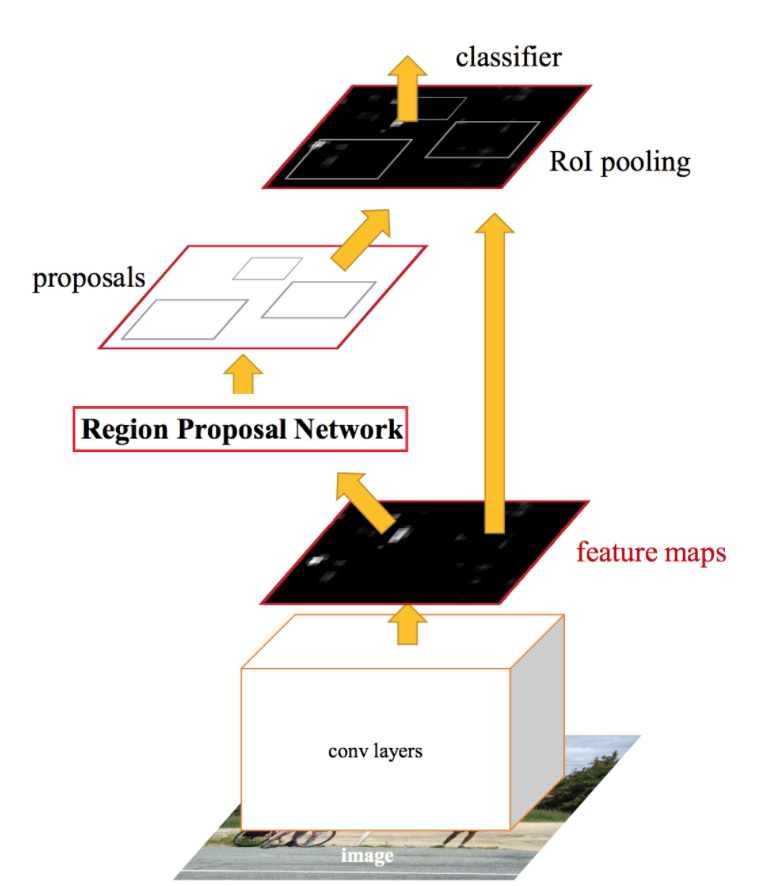
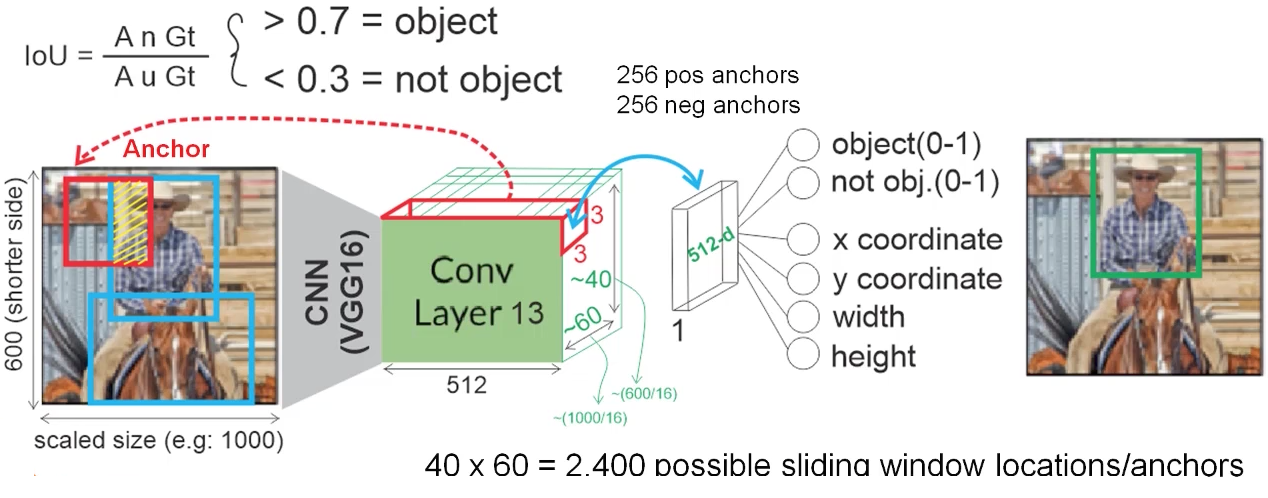
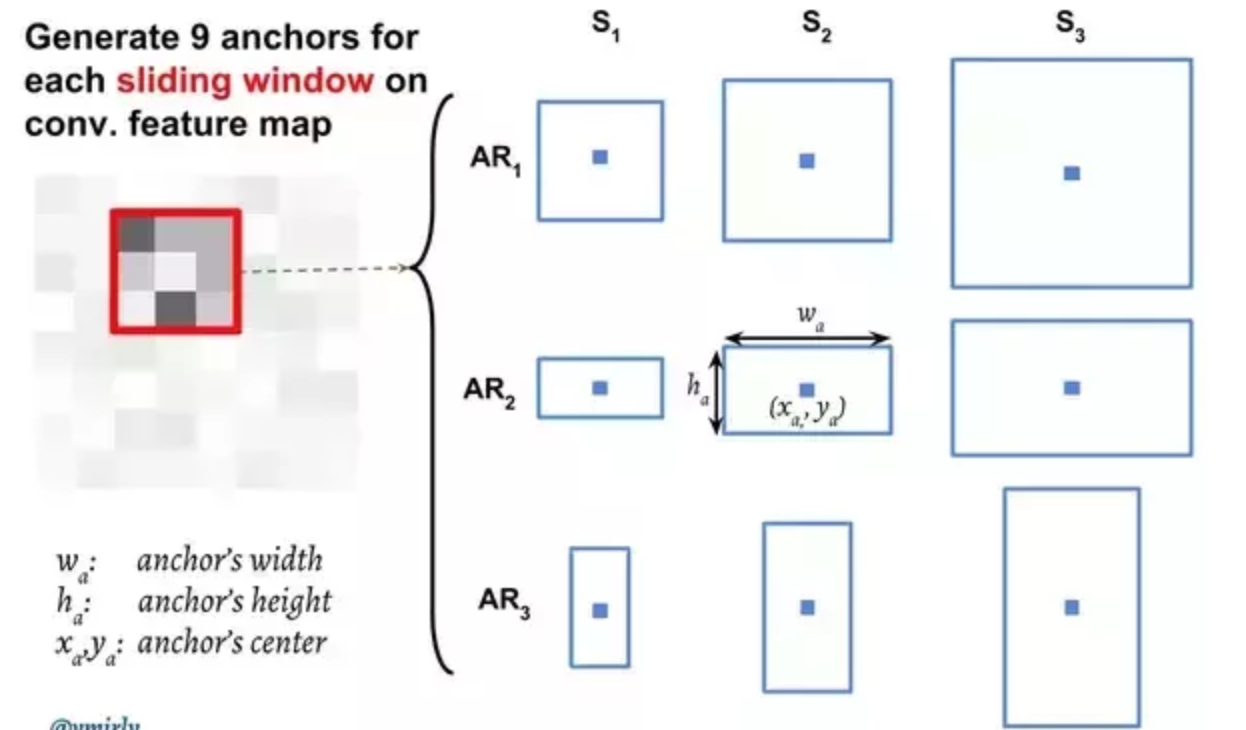
Faster R-CNN adds a Fully Convolutional Network on top of the features of the CNN creating what’s known as the Region Proposal Network. At the last layer of an initial CNN, some sliding windows move across the feature map and map it to a lower dimension. For each sliding-window location, it generates multiple possible regions based on k fixed-ratio anchor boxes. Each region proposal consists of an “objectness” score for that region and 4 coordinates representing the bounding box of the region.In other words, for each pixel in feature map, it takes k different boxes: a tall box, a wide box, a large box, etc. For each of those boxes, it outputs whether or not it contains an object, and what the coordinates for that box are.
Mask R-CNN
could we extend Faster R-CNN to also carry out pixel level segmentation?
Mask R-CNN adding a branch to Faster R-CNN that outputs a binary mask that says whether or not a given pixel is part of an object. The branch is just a Fully Convolution Network on top of a CNN based feature map. Output is a Matrix with 1s on all locations where the pixel belongs to the object and 0s elsewhere.The mask branch has a Km2-dimensional output for each RoI, which encodes K binary masks of resolution m × m, one for each of the K classes.
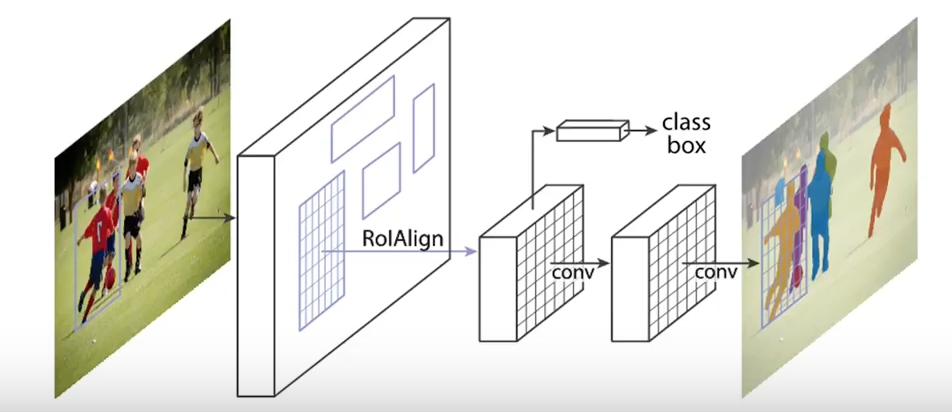
The RoIPool operation used for attending to each instance, has been modified to RoIAlign which avoids spatial quantization for feature extraction since keeping spatial-features intact in the highest resolution possible is important for semantic segmentation.
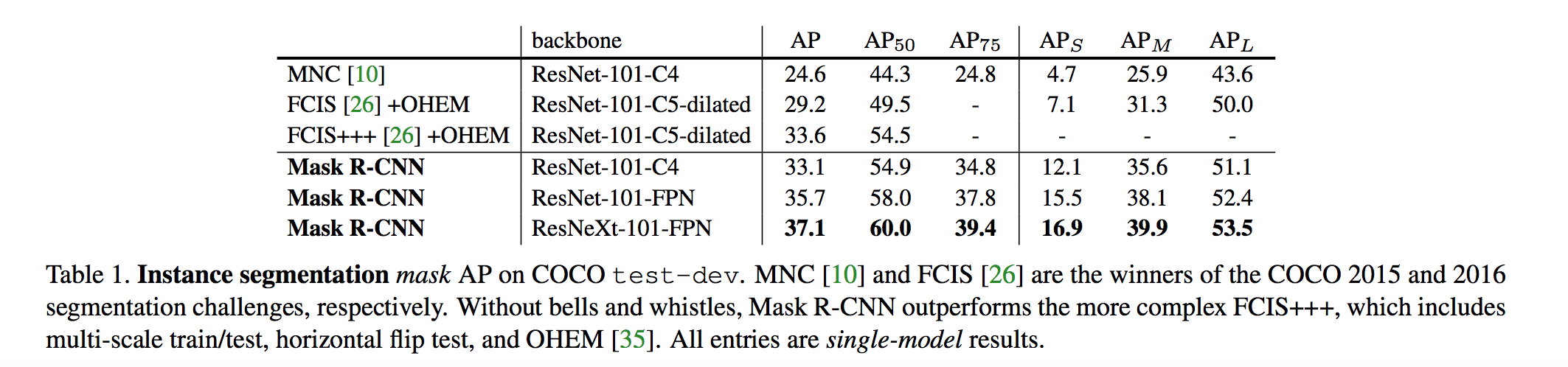
Results
NOTE :AP (averaged over IoU thresholds), and APS, APM, APL (AP at different scales).