Semi-Supervised Monocular Depth Map Prediction
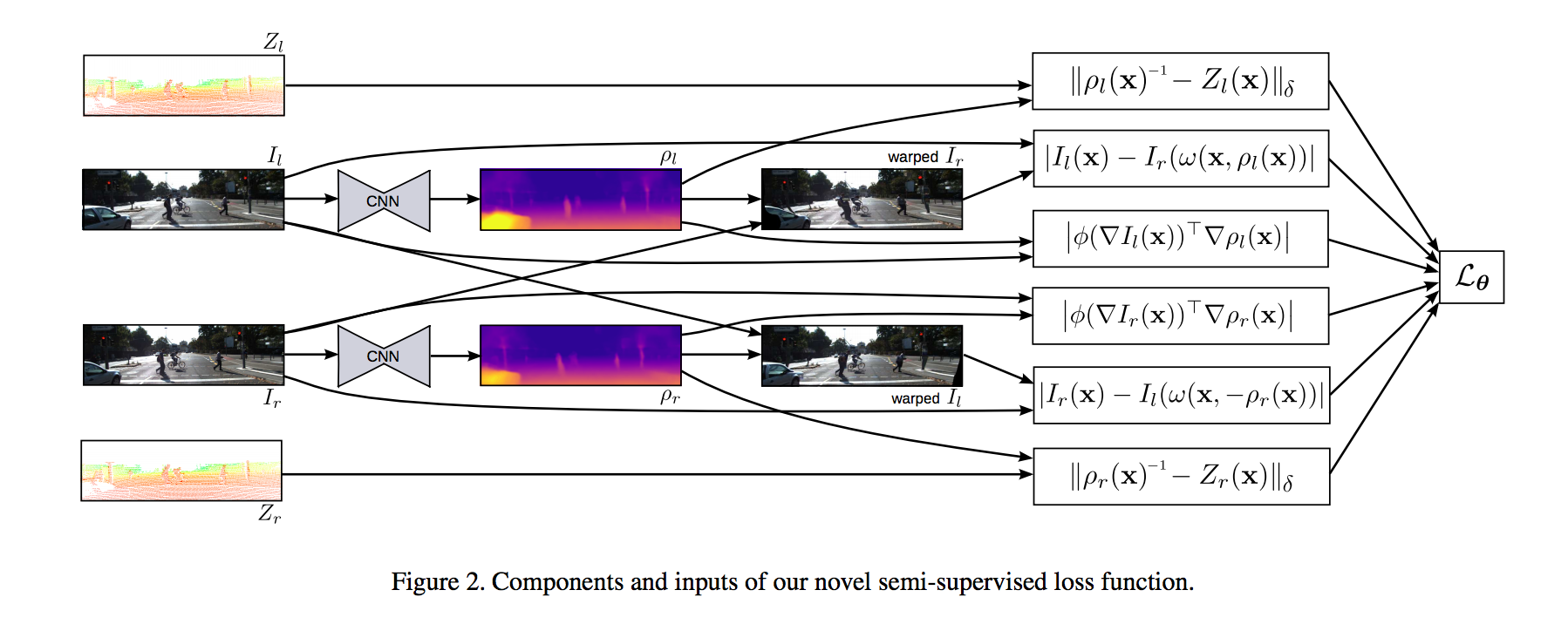
The authors propose a depth map prediction in a semi-supervised way for a monocular image. The network is a CNN (a deep residual network architecture in an encoder-decoder scheme) and output of the network is a disparity prediction (or inverse of depth).
The network is trained by unsupervised and supervised depth cues. The supervised part compares the output of network with the ground truth.
The unsupervised part learns depth prediction, directly from the stereo images that the left image was fed to the network, so with the left image and disparity (output of the network), each pixel from the left image can be mapped to the right image and inverse. Thus, the authors define loss by direct image alignment error in both directions in this part. We call unsupervised because the network does not use ground truth to calculate the loss].
An important note is that the author use BerHu-norm(https://arxiv.org/pdf/1207.6868.pdf) instead of L2-norm in supervised loss that performs better on test set and reduce the noise.

Results