Mimicking Very Efficient Network for Object Detection
This method proposes a form of compression by trying to mimic a big model with a small model. The method is really simple, they compute the distance between the last feature maps of both models as an added loss.
They use this technique on Inception for object detection. On Pascal VOC 2007, they suffer a 0.1% recall and a 3% precision loss with only half of the parameters. The non-mimick version had a 0.4% recall and 25% precision loss when fine-tuned from ImageNet.
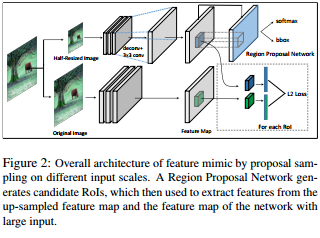
The authors did not compute the loss on empty regions. They mask the feature maps with the regions of interest detected by the Region proposal network. The loss is then normalized and added to the regular loss on the bounding boxes.
To further speed up the network, the small network has an input size reduced by half from the original. The final feature map is then upsampled by deconvolution.