Stacked Generative Adversarial Networks
Summary
Conditional GANs are trained to hierarchically generate an encoder’s internal representations by first conditioning on the class label (or encoding), down to generating the input image.
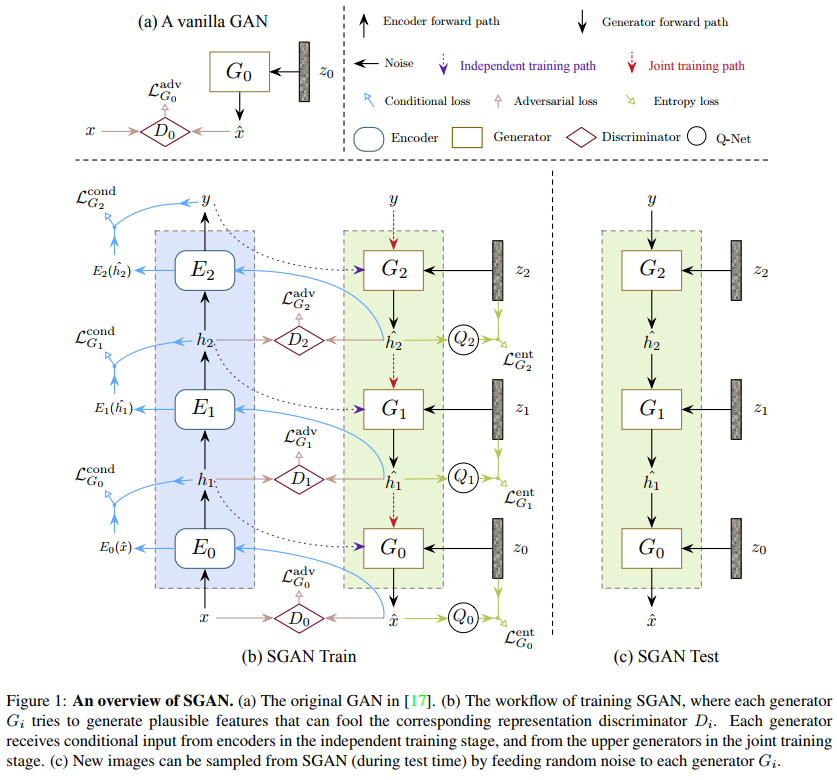
There are 3 combined types of losses:
- Adversarial loss: Each GAN-generated representation should be able to fool a discriminator when compared to the encoder-generated representations (purple arrows)
- Conditional loss: An encoder should produce the same higher representation whether its input was generated by a GAN or an encoder (blue arrows)
- Entropy loss: A new deep model \(Q_i\) (which shares parameters with \(D_i\)) tries to predict the GAN input noise given the GAN’s output \(Q_i( z_i\) | \(\hat{h}_i )\) (green arrows)
Training is done in two-steps to avoid the problem of having too much noise in the outputs at the beginning.
- Each GAN is trained separately (conditioned on the true last representation)
- All GANs are trained end-to-end (conditioned on the previous GAN’s generated representation)
Experiments and results
Datasets used: MNIST, SVHN, CIFAR-10
The authors show that without the entropy loss term, samples tend to be invariant to the input noise.


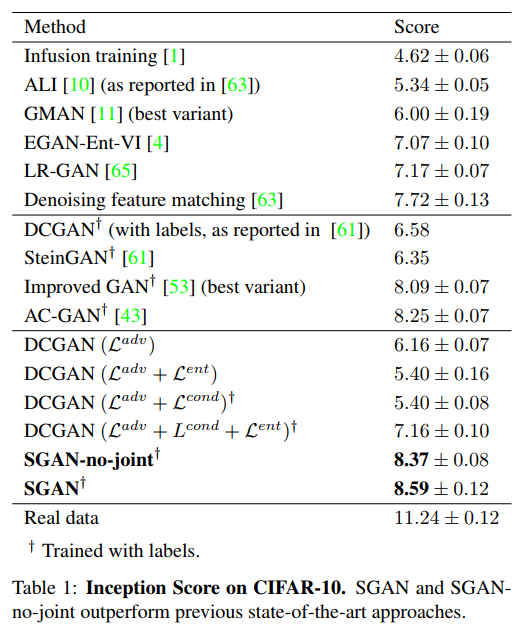
Their method beats the state-of-the-art Inception score on CIFAR-10. They also get a better “turing test” score on AMT than DC-GAN on MNIST and CIFAR-10 (24.4% error rate for SGAN vs. 15.6% for DC-GAN with the three combined losses).
Notes
SGANs depend on a good discriminator/encoder to learn good representations. I’d like to see results using unsupervised learning (perhaps using something like an auto-encoder).