FusionSeg: Learning to Combine Motion and Appearance for Fully Automatic Segmentation of Generic Objects in Videos
Two-stream model
Two-stream fully convolutional network for generic object segmentation in videos. One stream processes a single RGB image (appearance stream) and the other uses an optical flow RGB image (motion stream). The two streams are then combined in a single model (fusion model)
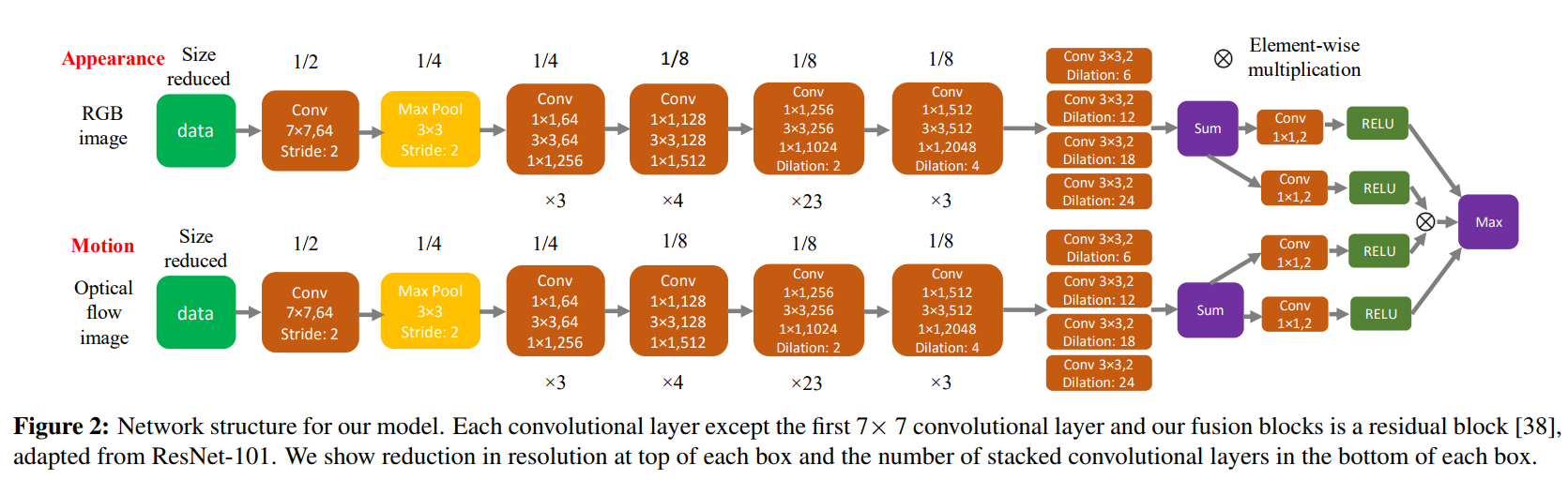
Each stream is based off a ResNet-101 pre-trained on image classification (ImageNet), where the last two groups of convolutions are replaced with dilated convolutions, and the classification layer is replaced with four parallel dilated convolutional layers (with different dilation parameters to handle objects of different scale).
The two streams are fused together using an ensemble model setup. The final prediction is made by taking the maximum of the appearance stream, the motion stream and the element-wise multiplication of the two (each preceded by a 1x1 conv + RELU). The idea is that either one of the two streams will have a strong confidence in its prediction, or the combination of both streams will allow for a confident prediction when the single streams don’t.
Training each stream
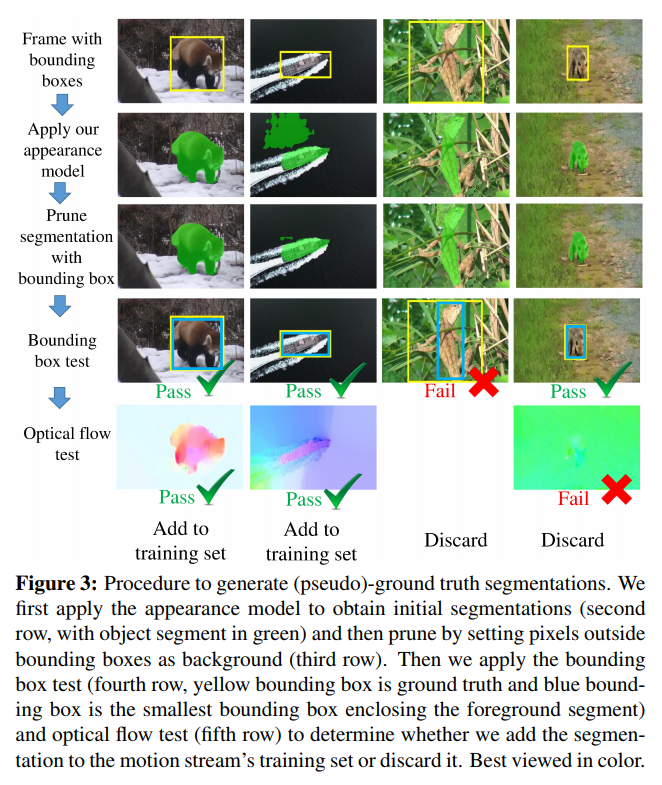
Each stream is initialized using pre-trained weights from ImageNet classification, then trained on its own before training the fusion model with few examples. Since annotated video data for the motion stream is very limited, a bootstrapping procedure is used to generate weakly-annotated images. This is done by combining a dataset of videos with bounding boxes and the appearance stream’s predictions (the appearance stream prediction is pruned using the bounding boxes, and the image is added to the motion stream’s training dataset if it passes both a bounding box and a meaningful optical flow test).
Results
Three datasets are used: DAVIS, Youtube-Objects and Segtrack-v2. Baselines are chosen from automatic methods (FST, KEY, NLC, COSEG) and semi-supervised methods (HVS, HBT, FCP, IVID, HOP, BVS).
Results show that the fusion model generally outperforms other methods, both automatic and semi-supervised (needing human interaction). Note, however, that no deep learning methods were included in the baselines.

Notes
It is unclear how they output a segmentation of the same size as the input image after all the size-reducing convolutions and max pooling… (The paper does not mention upsampling or deconvolutions.)