Full Resolution Image Compression with Recurrent Neural Networks
Idea
Use RNN-based encoder / decoder to perform image compression with different compression rates using a single model. The encoder is followed by a binarizer (Entropy coding binary PixelRNN) that stores the data with a minimal number of bits, so that the decoder can later on retrieve a lossy compression of the original image. The RNN architecture allows to control the amount of information: it increases at each iteration and a trade-off can be found between a stronger compression and a better reconstruction.
Method
Encoding network → Binarizer → Decoding network (E and D are RNN). Optimize them altogether on residual error.
One shot strategy:
\[\hat{x}_t = D_t(B(E_t(x-\hat{x}_{t-1})\]This is the progressive reconstruction of the original image x. Each successive iteration has access to more bits generated by the encoder, and leads to a better reconstruction.
Additive reconstruction:
\[\hat{x}_t = D_t(B(E_t(x-\hat{x}_{t-1}) + \hat{x}_{t-1}\]Each successive iteration adds to the previous estimation of the original image.
Application
Tested on Kodak uncompressed dataset (thumbnail sized images) / web images with : LSTM, Associative LSTM, Residual GRU (one shot networks and additive reconstruction networks). Images with the worst compression ratio (High entropy) with PNG are sorted out and used as a different train set. They show that the models benefit from being trained extensively on hard cases.
The metrics used for image compression try to reflect the human eye sensitivity (Peak Signal to Noise Human Visual System, Multi-scale Structural Similarity) but nothing compares to visual impression so additional materials are given at sup.
Depending on metrics, the one shot version of LSTM and residual GRU appear to be the most promising architectures. All models benefit from the entropy coding layer.
Even without entropy coding, this is the first architecture able to outperform JPEG compression.
Architecture :
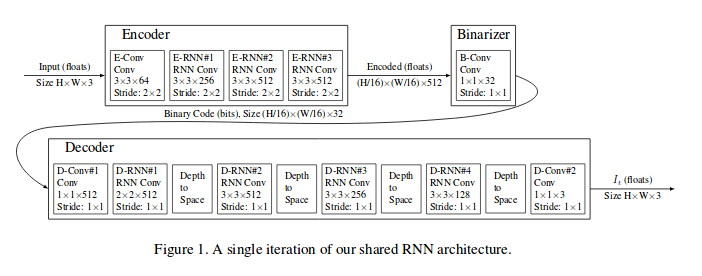
Visual examples:
