Dilated Residual Networks
In this paper, the authors show that using dilated convolution help to produce better results for image classification, object localization, and image segmentation. Also, the dilated convolution is kind of plug-and-play in place of regular convolution with minor changes in the network.
The dataset used for the image classification and object localization is ImageNet 2012 and for the image segmentation it’s CityScapes.
The main idea of this paper is to help the network preserve the spatial resolution of its input.
Models
The model is a regular ResNet to produce baseline results for the different tasks.
The first model called DRN-A removes the last maxpooling layer and uses only dilated convolutions with different dilation rates to have the same receptive field as the maxpooling network but with a larger feature maps output. The figure below presents these changes.
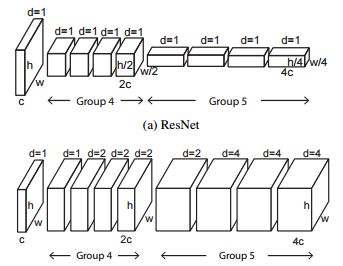
We can see that they use different dilation rates to mimic the maxpooling operation.
The main idea to produce larger feature maps is that even a human in an image of 28x28 can detect useful information and so take a decision. So instead of having feature maps of size 8x8, the dilated convolutions produce feature maps of size 28x28.
Unfortunately, the DRN-A network has an issue, the dilated convolutions produce gridding artifacts in the localization task. To solve this problem, they derive this model in two version, DRN-B and DRN-C. DRN-B add layers and remove some maxpooling operations. DRN-C based on (DRN-B) remove the residual connection in the latter layers to filter these artifacts.

Results
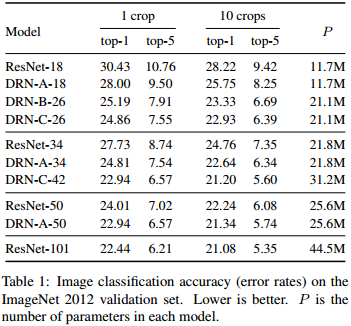
Here is a summary of the results obtained by the different networks for the three datasets. For the classification task, they improve the accuracy of the network with the same number of parameters and layers. They achieve almost the same accuracy than a much deeper network (ResNet101) with only half of its parameters.
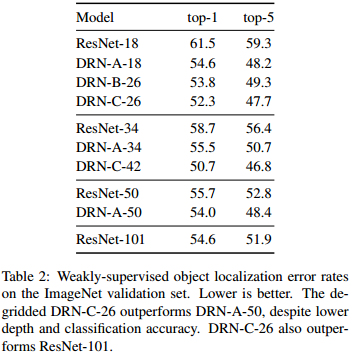
For the weakly-supervised localization, the results show the same improvement than for the classification task.
Larger feature maps improves the classification accuracy over a much deeper resnet.
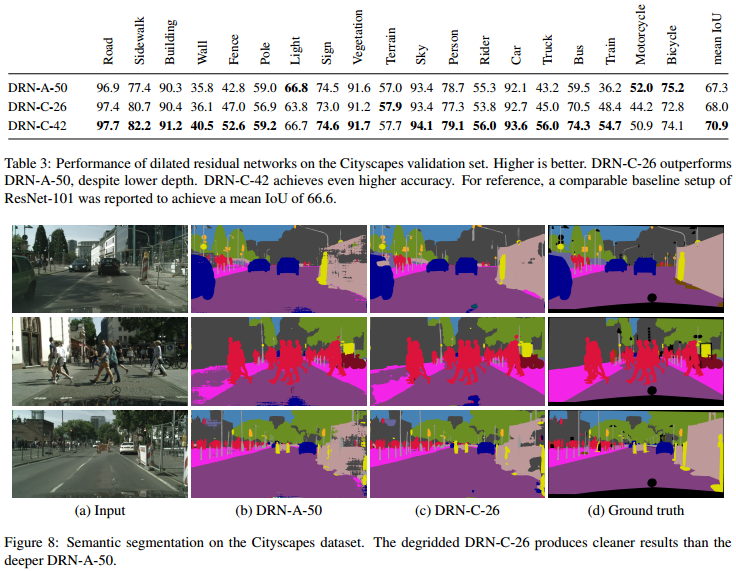
They didn’t report the ResNet101 detailed results, only its overall mean IoU for the segmentation task.
Their model on average produces better IoU than the ResNet.
The segmentation produced by the DRN-C is better that their DRN-A architecture. We don’t know for DRN-B, it may be better or worst…