Scale-Aware Face Detection
This paper addresses a face detection problem and test their model on three face detection datasets, Face Detection Data Set and Benchmark (FDDB), Multi-Attribute Labelled Faces (MALF) and Face Detection, Pose Estimation and Landmark Localization in the Wild (AFW).
Models
They split the problem in two smaller ones. They use a network to detect the scale of faces in the image and another one to place bounding box on these faces.
Scale Proposal Network (SPN)
First, they use a CNN model (SPN) to predict an histogram of scales of faces in the image, as shown in Fig.3.
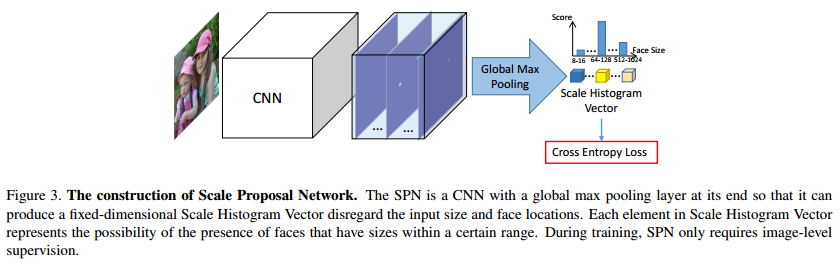
They refine the prediction of the SPN by smoothing it with a moving average and use the non max supression algorithm to have fewer scales as shown in Fig.4.
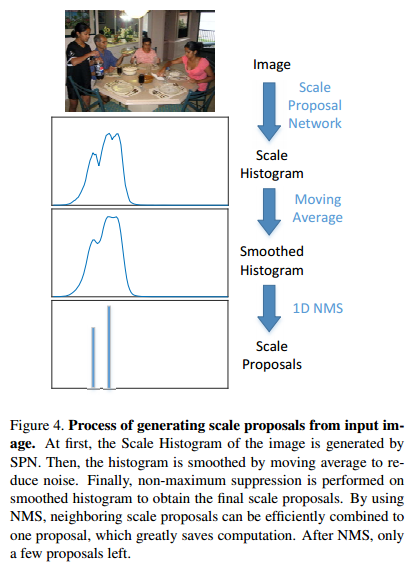
Region Proposal Network (RPN)
With the scale proposals produced by the SPN, they rescale the image given the scaling histogram and predict the boundingbox face for all the rescaled images with the Single Scale RPN as in Fig.2.
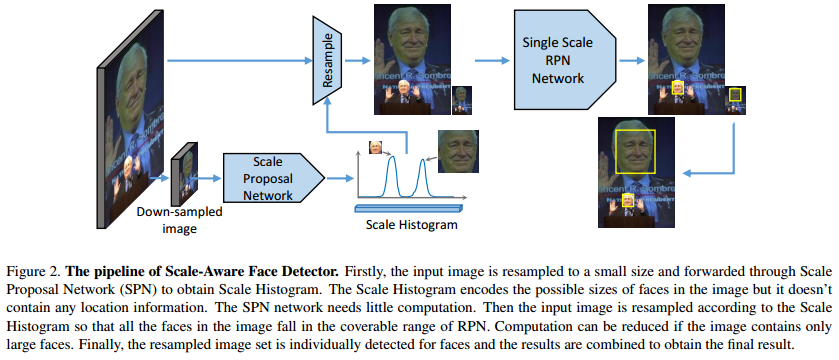
They use Faster r-cnn as their RPN method (paper, code). The inner network for these two models is made from GoogleNet.
Training
They generate the bounding box from facial landmarks to avoid the noise added when doing manual bounding box annotation. These landmarks are left eye center, right eye center, nose, left mouth corner and right mouth corner. Each bounding box generated are square.
For the scaling vector used in the SPN they use a gaussian function centered on the ground truth face size.
Results
They report SOTA results on the three datasets with a mean recall of 88.15% and an average precision of 98.77%.