The Marginal Value of Adaptive Gradient Methods
Adaptive optimization methods, which perform local optimization with a metric constructed from the history of iterates, are becoming increasingly popular for training deep neural networks. Examples include AdaGrad, RMSProp, and Adam.
As their first contribution, the authors construct a binary classification problem where the data is linearly separable, and prove that for this problem, (stochastic) gradient descent achieve zero error, and AdaGrad, Adam and RMSProp attain test errors close to 50%.
As a second contribution, authors compare the empirical “generalization capability” of the methods on four state-of-the-art deep learning models, one of which is a CNN designed for CIFAR-101. Here are some of their findings:
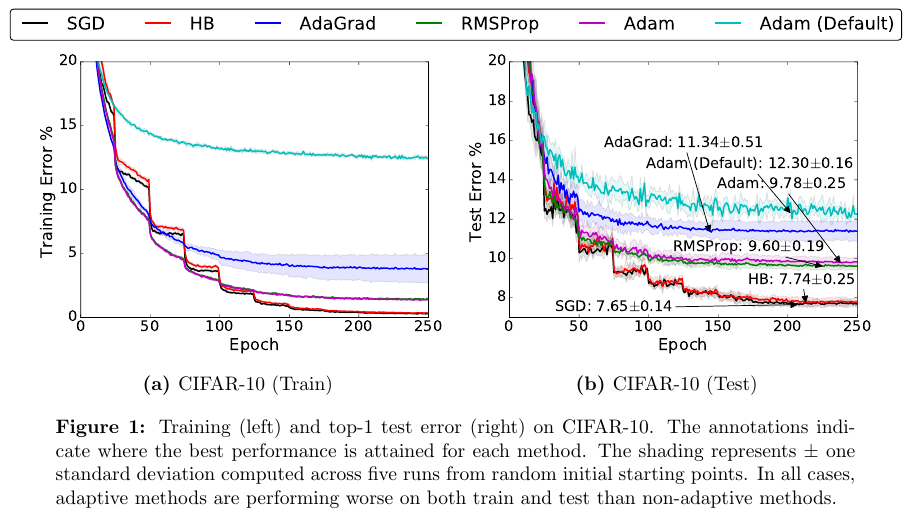
- Adaptive methods find solutions that generalize worse than those found by non-adaptive methods.
- Adaptive methods often display faster initial progress on the training set, but their performance quickly plateaus on the development set.
- Though conventional wisdom suggests that Adam does not require tuning, we find that tuning the initial learning rate and decay scheme for Adam yields significant improvements over its default settings in all cases.
All of these findings seem to contradict Stanford’s CS231n course material. In the 2016 version of this course, the presentation of RMSProp and Adam suggest that those methods converge faster, without notable drawbacks.
In the figure below, “HB” stands for Polyak’s heavy-ball method, which is considered to be part of the stochastic momentum methods.
Lastly, the authors suggest a method for tuning the initial step size \(\alpha_0\) that worked well in all of their experiments. To find \(\alpha_0\), the authors conduct a grid search with \(\alpha_0 = 2^k\) over five consecutive values of \(k \in \mathbb{Z}\). If the best performance is achieved at one extreme of the grid, they try new grid points so that the best performance is contained in the middle of the grid.
-
The model is cifar.torch. They say it is state-of-the-art but this is not correct. It has a classification accuracy 1% worse than ResNet (source). ↩