Tiramisu-Net: The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation
This paper implements all the well-known advances in deep learning segmentation methods and make it work together on the CamVid and Gatech datasets.
The proposed network implements the following things:
- Dense blocks
- U-Net architecture
Dense blocks
The dense block provides a low increase of parameters while keeping a good feature extraction.
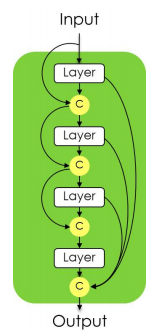
U-Net
The U-Net is well-known to have a good performance on various image segmentation datasets.
Architecture
The network architecture is a straight U-Net with more convolution stages in each step.

In the following table, \(m\) represents the number of feature maps output, DB means dense block, TD means transition down and TU means transition up.
Layers
Here is the internal description of all the blocks defined above.

Results
Overall the model is as accurate than the other state-of-the-art models while having much fewer parameters (100x less for some of them).
Issues
Even if the model has fewer parameters than the others models, you should keep in mind that it still has far more layers than a regular U-Net so the memory footprint is huge when you want to train it.
If you run it on theano you should use some THEANO_FLAGS like optimizer_including=fusion to decrease the memory footprint and use a smaller batch_size.
Implementations
This original Theano/Lasagne implementations of the paper can be found here FC-DenseNet.
This is my personal Keras/notebook contribution implementation.