Inception-v3 : Rethinking the Inception Architecture for Computer Vision
The main contribution of this paper is the factorized convolutions. In Inception-v1, the authors use bigger kernel sizes in their architecture, which are computationally expensive.
In Inception-v2, the authors propose to factorize all kernels bigger than 3 to multiple 3x3 kernels. So a 5x5 kernel would become two 3x3. Here’s a figure showing the inception module from Inception-v2.
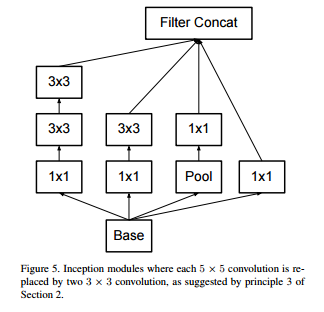
The authors also changed Inception-v1 to do max-pooling before the inception module. This saves memory and is 2 times faster.
Another speed-up is to take every nxn kernel and create a nx1 and a 1xn kernel. This is a 33% speedup according to the authors. This approach works best on later stages of the network.
Inception-V3
The Inception-v3 model is a simple extension from Inception-v2 and is the one recommended to use. While Inception-v2 has BatchNorm only in the convolutional layers, Inception-v3 adds BatchNorm after every dense layer as well.
Results
At the time of the publication, Inception-v3 achieved state-of-the-art on ImageNet with a top-1 error of 17.2% and a top-5 error of 3.58%.