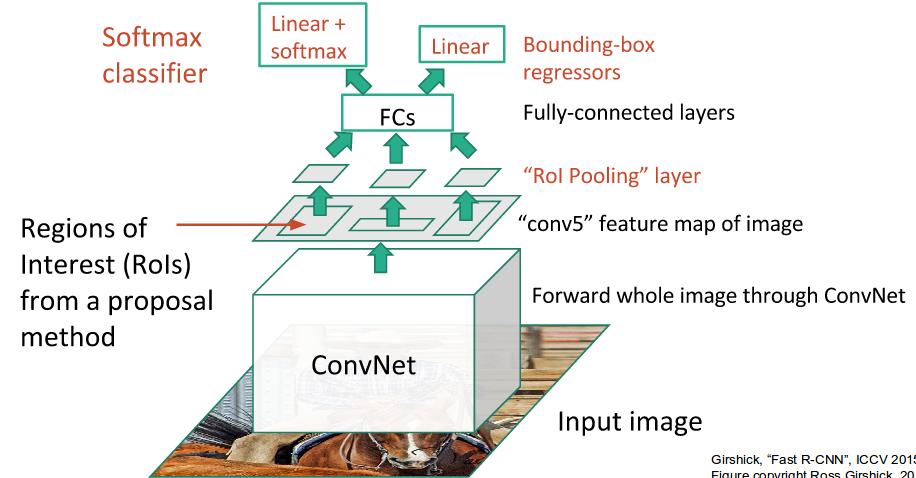
Fast R-CNN
This is an effort to improve R-CNN. Instead of feeding prospective bounding boxes to a CNN+SVM, the input image is fed to a VGG16 net. At the conv5 layer, each bounding box is used sequentially to crop the feature maps, followed by an ROI Pooling layer in order to resize the croped feature maps. This is followed by the usual FC layers + softmax. A bounding box regressor is also used to reposition the bounding boxes.
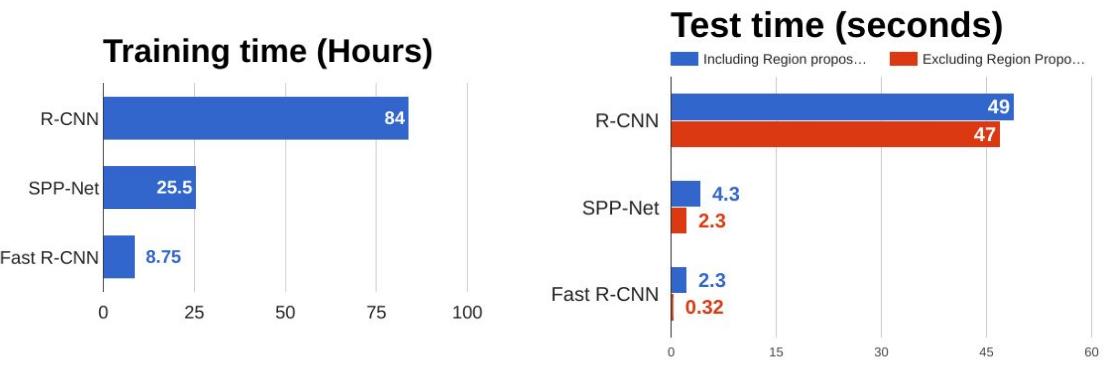
While results are slightly better than R-CNN on VOC 2017/10/12, Fast R-CNN is much faster both at train time and at test time.
Other stuff
Warning! code no longer maintained!