DeepMask : Learning to Segment Object Candidates
This paper presents the DeepMask architecture, which can be used as an object detection method when combined with R-CNN.
DeepMask works on a patch-based approach. For each patch, the model tries to predict two things. First of all, the model outputs a pixel-wise segmentation map to find salient objects. Then, in another branch, the model predicts if the patch is at the center of the object. This allows overlapping objects of the same class to be segmented independently.
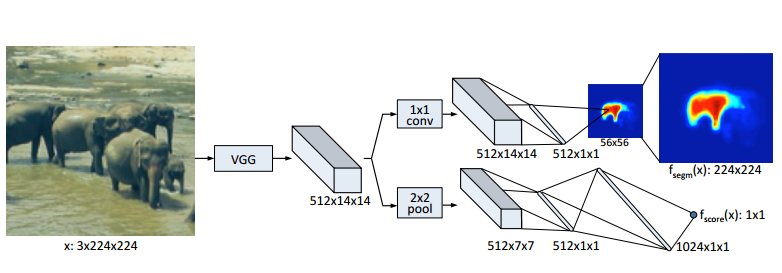
The authors propose two models, DeepMask and DeepMaskZoom. The later uses smaller scales to improve performance on smaller objects. This comes at a cost of increased inference time (not provided by the authors). DeepMask runs at 1.6s by image.
Training
The authors only trained on positive patches. This means that there is an object in every training patch. This does not mean that the object is centered.
The authors argue that using only positive patches forces the model to segment every image.
Results
DeepMask can be used as an object detection method when combined with R-CNN. At the time, DeepMaskZoom was state of the art on MS COCO for box proposals and segmentation proposals.