Feature Pyramid Networks for Object Detection
The Feature Pyramid Network (FPN) looks a lot like the U-net. The main difference is that there is multiple prediction layers: one for each upsampling layer. Like the U-Net, the FPN has laterals connection between the bottom-up pyramid (left) and the top-down pyramid (right). But, where U-net only copy the features and append them, FPN apply a 1x1 convolution layer before adding them. This allows the bottom-up pyramid called “backbone” to be pretty much whatever you want. In their experiments, the authors use Resnet-50 as their backbone.
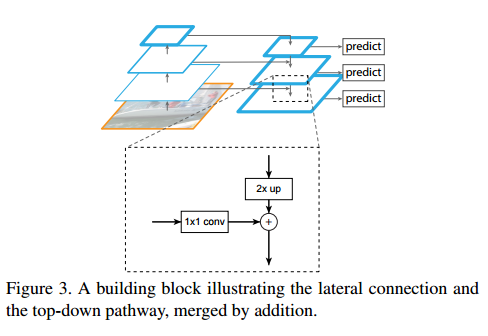
FPN for region-proposal
To achieve region-proposal, the authors add a 3x3 Conv layer followed by two 1x1 Conv for classification and regression on each upsampling layer. These additions are called heads and the weights are shared. For each head, you assign a set of anchors boxes resized to match the head’s shape. The anchors are of multiple pre-defined scales and aspect ratios in order to cover objects of different shapes. Training labels are then assigned to each anchor based on the IoU. A positive label is assigned if the IoU is greater than 70%.
FPN for object Detection
Using Fast(er) R-CNN, they can use FPN as the region proposal part. The proposals are used in combination with RoiPooling and then they can do the same work as Fast(er) R-CNN.
Results
Faster R-CNN on FPN with a ResNet-101 backbone is achieving state of the art on the COCO detection benchmark. It’s also faster than Resnet-101 Faster R-CNN by a significant margin because of the weight sharing in the heads.
Effect of lateral connections
FPN performs better than a normal Conv-Deconv because the Conv-Deconv’s feature maps are wrong according to the authors. Indeed, they argue that the locations of these maps are not precise, because these maps have been downsampled and upsampled several times. There is a 10% jump in accuracy using lateral connections.