Learning Deconvolution Network for Semantic Segmentation
This paper presents a neural network for semantic segmentation and classification. To achieve this they implement two new operations, the unpooling given a pooling map and the deconvolution.
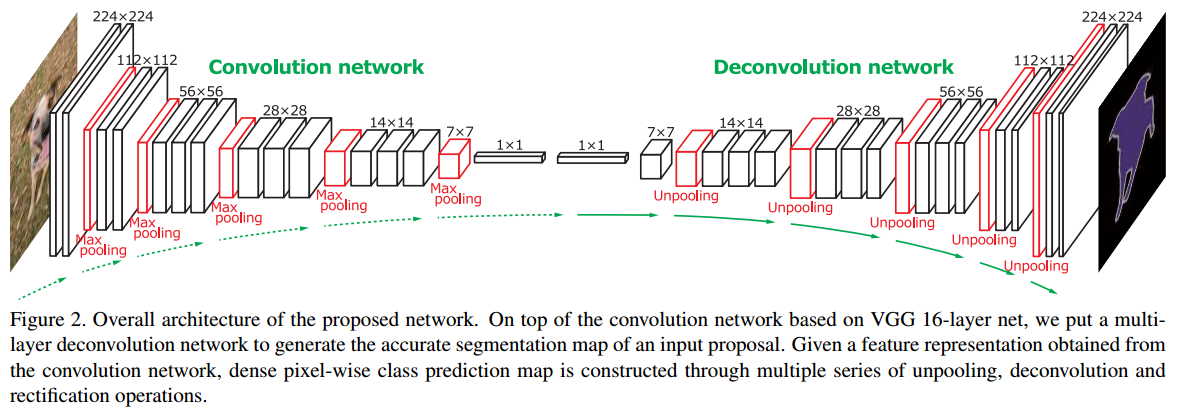
Architecture
It is a symmetric VGG16 where on the left-end side it’s the regular VGG16 and on the right-end side it’s the same architecture with unpooling layer (see Figure 2) and deconvolution.
Unpooling
When they process each maxpooling layer, they record the locations of maximum activations inside a pooled map for each maxpooling layer. They use these pooled maps during the unpooling operation to retrieve the spatial information loss in the pooling operation (see Figure 3).
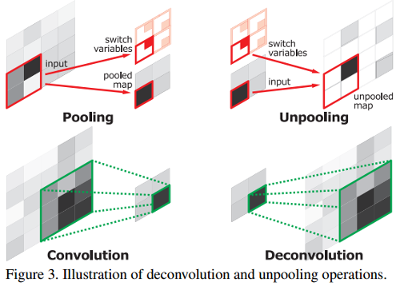
Deconvolution
As shown in Figure 2 the deconvolution network is made of unpooling layers and deconvolution layers. The deconvolution is the operation to map one pixel into a higher dimensional space (see Figure 3). It is literally the opposite operation of the usual convolution. They crop the boundary of the enlarged activation of each deconvolution layer to keep the same size as the output of the previous unpooling layers.
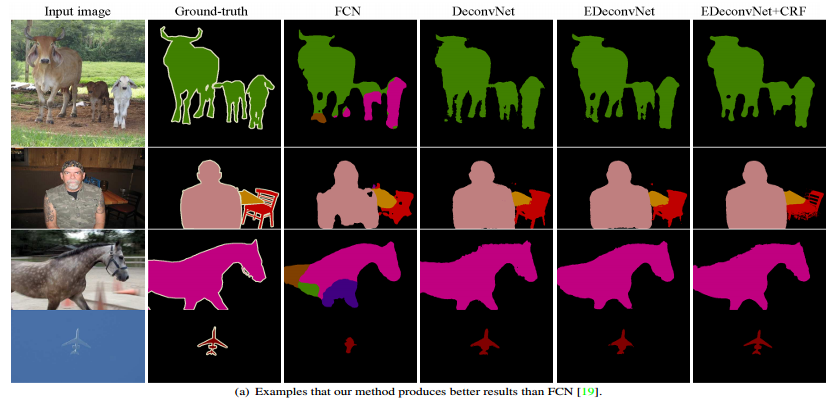
Results
The results of their network are quite accurate and they try different post processing methods to enhance their prediction.