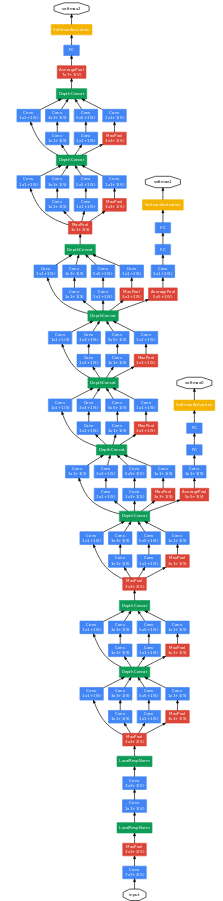
GoogLeNet, Inception (Going Deeper with Convolutions)
Winner of the ILSVRC 2014 competition, both for the classification and the localization. The main novelty of this paper is the use of inception layers which is a series of conv layers with different receptive fields.
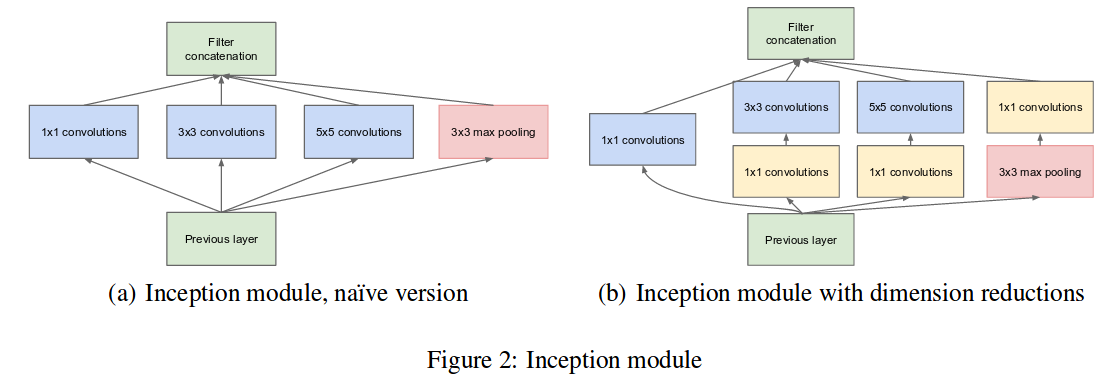
Figure 2 (a) shows a naive implementation of an inception module. The authors argue that the use of a 1x1 convolution before the nxn spatial convolution gives better results while reducing the number of parameters. The full network is given below. The use of several outputs (3 softmax) encourages discrimination in the lower stages. At test time, only the last output it kept. The approach taken by GoogLeNet for localization is similar to that of R-CNN.